CTE 與子查詢:PostgreSQL 的查詢組合與遞迴能力 | PostgreSQL
2026/06/25
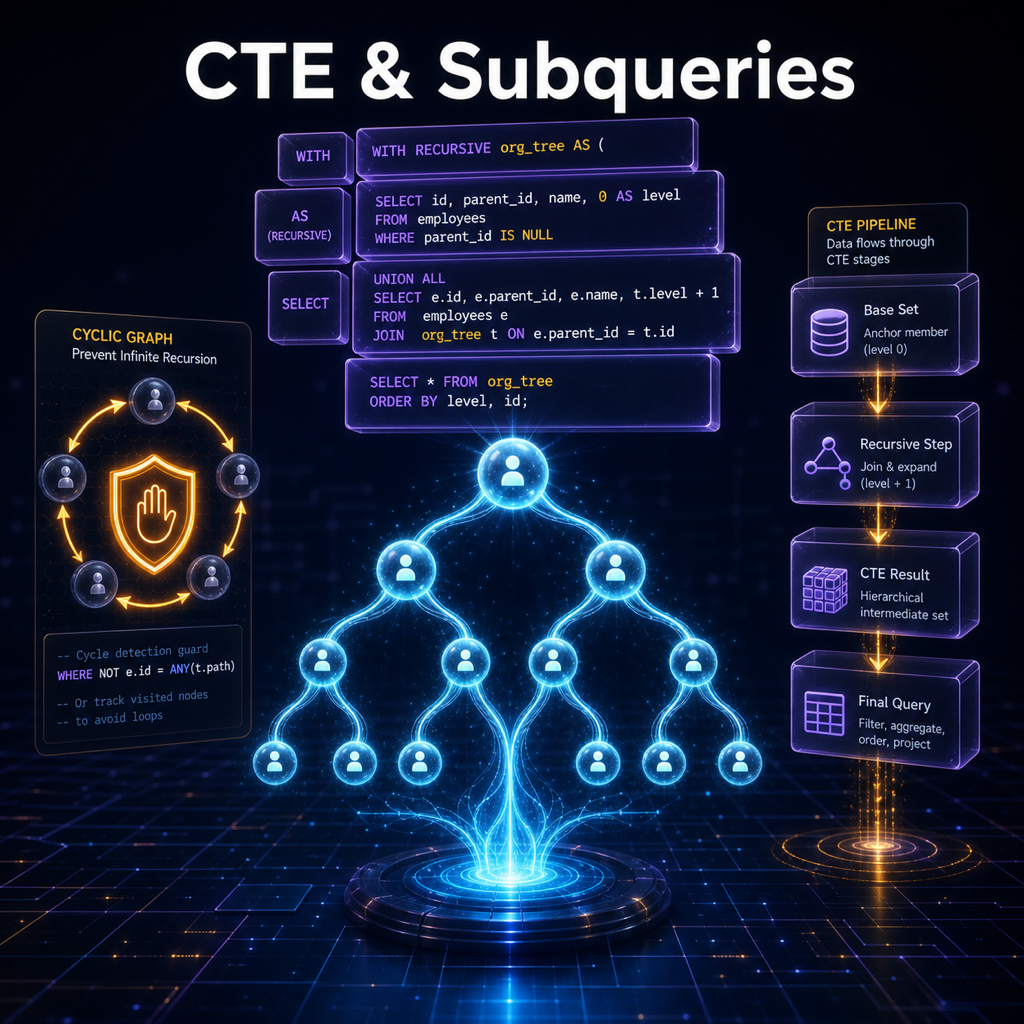
CTE(Common Table Expression) 透過
WITH子句定義命名暫時結果集,讓複雜查詢更具可讀性。PostgreSQL 在 CTE 上提供了 Materialized / Inline 智慧型決策(PG12+)、強大的 遞迴 CTE 支援,以及獨特的 可寫 CTE(WITH … INSERT/UPDATE/DELETE)能力,搭配子查詢的 EXISTS / IN / ANY 語義,是組合複雜查詢邏輯的利器。
CTE 執行模型:Materialized vs Inline
PostgreSQL 執行 CTE 時有兩種策略:
| 策略 | 行為 | 優勢 | 劣勢 |
|---|---|---|---|
| Materialized | CTE 結果實際計算並快取 | 多次引用只算一次 | 無法利用外層 WHERE 下推 |
| Inline | CTE 展開為子查詢 | 規劃器可整合最佳化、利用索引 | 多次引用可能重複計算 |
PG12 之前:所有 CTE 強制 Materialized,形成「優化障壁(Optimization Fence)」。
PG12 起:規劃器依據以下規則自動判斷:
- 只被引用一次且無副作用 → 預設 Inline
- 含副作用(INSERT/UPDATE/DELETE)或被引用多次 → 預設 Materialized
- 可用
MATERIALIZED/NOT MATERIALIZED手動覆蓋
-- 強制 Materialized:CTE 結果只計算一次
WITH expensive_cte AS MATERIALIZED (
SELECT customer_id, SUM(amount) AS total_spent
FROM orders
GROUP BY customer_id
HAVING SUM(amount) > 1000
)
SELECT c.name, e.total_spent
FROM expensive_cte e
JOIN customers c USING (customer_id)
WHERE c.region = 'Asia';
-- 強制 NOT MATERIALIZED:讓外層條件下推至 CTE 內
WITH customer_orders AS NOT MATERIALIZED (
SELECT customer_id, order_date, amount
FROM orders
)
SELECT *
FROM customer_orders
WHERE customer_id = 42 -- 此條件可下推,利用索引
AND order_date >= '2025-01-01';
-- PG11 及之前的效能問題
WITH all_users AS (
SELECT * FROM users -- 強制全表掃描!
)
SELECT * FROM all_users WHERE id = 42;
-- PG12+ 自動 Inline,可利用主鍵索引
多 CTE 串連
後面的 CTE 可引用前面的 CTE,形成步驟化的資料處理管線:
WITH
-- CTE 1:計算各部門平均薪資
dept_avg AS (
SELECT department_id, AVG(salary)::NUMERIC(10,2) AS avg_salary
FROM employees
GROUP BY department_id
),
-- CTE 2:找出高於部門平均的員工
above_avg AS (
SELECT e.employee_id, e.name, e.salary, d.avg_salary
FROM employees e
JOIN dept_avg d USING (department_id)
WHERE e.salary > d.avg_salary
),
-- CTE 3:附加部門名稱
final_result AS (
SELECT a.name, a.salary, a.avg_salary, dep.department_name
FROM above_avg a
JOIN departments dep USING (department_id)
)
SELECT * FROM final_result ORDER BY salary DESC;
遞迴 CTE 的執行機制
遞迴 CTE 使用 WITH RECURSIVE 語法,透過反覆迭代建構結果集:
WITH RECURSIVE cte AS (
<非遞迴基底部分> ← 只執行一次,產生初始結果集
UNION ALL
<遞迴部分> ← 反覆執行,直到無新資料產生
)
執行流程:
Step 1:執行基底部分 → 結果放入 Working Table
│
Step 2:Working Table 非空?
YES → 以 Working Table 為輸入執行遞迴部分
│
├─ 新結果暫存至 Intermediate Table
├─ 將 Intermediate Table 附加到最終結果集
└─ 用 Intermediate Table 取代 Working Table → 回到 Step 2
NO → 結束迭代,返回完整結果集
重要特性:
- 遞迴部分只能讀取 Working Table,不能引用最終累積結果集
UNION ALL允許重複列;UNION每步去除重複,效能較差- 必須有終止條件,否則無窮迴圈
遞迴 CTE 實戰:組織樹
-- 資料表
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(100),
manager_id INT REFERENCES employees(id)
);
INSERT INTO employees VALUES
(1, 'Alice', NULL), -- CEO
(2, 'Bob', 1),
(3, 'Charlie', 1),
(4, 'David', 2),
(5, 'Eve', 2),
(6, 'Frank', 3);
-- 從 CEO 向下展開整棵組織樹
WITH RECURSIVE org_tree AS (
-- 基底:根節點
SELECT
id, name, manager_id,
0 AS depth,
ARRAY[id] AS path,
name::TEXT AS full_path
FROM employees
WHERE manager_id IS NULL
UNION ALL
-- 遞迴:下一層員工
SELECT
e.id, e.name, e.manager_id,
ot.depth + 1,
ot.path || e.id,
ot.full_path || ' > ' || e.name
FROM employees e
JOIN org_tree ot ON e.manager_id = ot.id
WHERE e.id <> ALL(ot.path) -- 防止循環引用
)
SELECT
repeat(' ', depth) || name AS indented_name,
depth, full_path
FROM org_tree
ORDER BY path;
-- 結果:
-- indented_name depth full_path
-- Alice 0 Alice
-- Bob 1 Alice > Bob
-- David 2 Alice > Bob > David
-- Eve 2 Alice > Bob > Eve
-- Charlie 1 Alice > Charlie
-- Frank 2 Alice > Charlie > Frank
遞迴 CTE 實戰:BOM 展開
-- 物料清單:產品由零件組成,零件本身也可有子零件
CREATE TABLE bom (
parent_id INT,
child_id INT,
quantity INT
);
WITH RECURSIVE bom_expand AS (
-- 基底:頂層產品的直接零件
SELECT child_id, quantity, 1 AS level,
quantity::NUMERIC AS total_qty
FROM bom
WHERE parent_id = 100
UNION ALL
-- 遞迴:展開子零件,累積數量
SELECT b.child_id, b.quantity, be.level + 1,
be.total_qty * b.quantity -- 累積乘積計算實際用量
FROM bom b
JOIN bom_expand be ON b.parent_id = be.child_id
)
SELECT child_id AS part_id, level,
SUM(total_qty) AS total_required
FROM bom_expand
GROUP BY child_id, level
ORDER BY level, child_id;
防止無窮迴圈
方法一:路徑陣列偵測
WITH RECURSIVE safe_tree AS (
SELECT id, manager_id, ARRAY[id] AS path
FROM employees WHERE id = 1
UNION ALL
SELECT e.id, e.manager_id, st.path || e.id
FROM employees e
JOIN safe_tree st ON e.manager_id = st.id
WHERE e.id <> ALL(st.path) -- 已在路徑中則停止
)
SELECT * FROM safe_tree;
方法二:PG14+ CYCLE 子句
WITH RECURSIVE org_tree AS (
SELECT id, name, manager_id
FROM employees WHERE manager_id IS NULL
UNION ALL
SELECT e.id, e.name, e.manager_id
FROM employees e
JOIN org_tree ot ON e.manager_id = ot.id
)
CYCLE id SET is_cycle USING cycle_path -- 原生循環偵測
SELECT id, name, cycle_path
FROM org_tree
WHERE NOT is_cycle;
方法三:深度限制
WITH RECURSIVE limited_tree AS (
SELECT id, manager_id, 0 AS depth
FROM employees WHERE id = 1
UNION ALL
SELECT e.id, e.manager_id, lt.depth + 1
FROM employees e
JOIN limited_tree lt ON e.manager_id = lt.id
WHERE lt.depth < 10 -- 最多 10 層
)
SELECT * FROM limited_tree;
PG14+ SEARCH 子句:控制遍歷順序
WITH RECURSIVE org_tree AS (
SELECT id, name, manager_id
FROM employees WHERE manager_id IS NULL
UNION ALL
SELECT e.id, e.name, e.manager_id
FROM employees e
JOIN org_tree ot ON e.manager_id = ot.id
)
-- SEARCH DEPTH FIRST:深度優先遍歷
-- SEARCH BREADTH FIRST:廣度優先遍歷
SEARCH DEPTH FIRST BY id SET ordercol
SELECT id, name, ordercol
FROM org_tree
ORDER BY ordercol;
EXISTS vs IN vs ANY 選擇指引
EXISTS:半連接語義
-- EXISTS:只關心「是否存在」,找到第一筆匹配即停止
SELECT c.customer_id, c.name
FROM customers c
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
AND o.amount > 1000
);
-- EXISTS 不受 NULL 影響,是最安全的存在性檢查
IN:適合小型列表
-- IN 搭配靜態列表
SELECT * FROM employees
WHERE department_id IN (1, 2, 5, 10);
-- IN 搭配子查詢:規劃器可能轉為 Hash Semi Join
SELECT * FROM employees
WHERE department_id IN (
SELECT id FROM departments WHERE location = 'Taipei'
);
NOT IN 的 NULL 陷阱
-- ⚠️ 若子查詢包含 NULL,NOT IN 可能返回空結果集!
-- 原因:x NOT IN (1, 2, NULL) → x<>1 AND x<>2 AND x<>NULL
-- x<>NULL 永遠為 UNKNOWN,整個條件為 UNKNOWN
SELECT * FROM employees
WHERE department_id NOT IN (
SELECT id FROM departments -- 若有 NULL 的 id,結果為空!
);
-- ✅ 安全替代:使用 NOT EXISTS
SELECT * FROM employees e
WHERE NOT EXISTS (
SELECT 1 FROM departments d
WHERE d.id = e.department_id
);
ANY / ALL:搭配比較運算子
-- = ANY 等同於 IN
SELECT * FROM employees
WHERE department_id = ANY (ARRAY[1, 2, 5]);
-- > ANY:大於子查詢中的最小值
SELECT name, salary FROM employees
WHERE salary > ANY (
SELECT AVG(salary) FROM employees GROUP BY department_id
);
-- > ALL:大於子查詢中的所有值(即大於最大值)
SELECT name, salary FROM employees
WHERE salary > ALL (
SELECT AVG(salary) FROM employees GROUP BY department_id
);
選擇指引:
| 運算子 | 適用場景 |
|---|---|
EXISTS | 確認存在性、子查詢大且能早期退出、含 NULL 安全 |
IN | 靜態小列表、子查詢不含 NULL |
NOT IN | 危險! 子查詢有 NULL 時返回空集合,改用 NOT EXISTS |
= ANY | 功能同 IN,可搭配陣列語法 |
> ANY / < ANY | 大於最小值 / 小於最大值 |
> ALL / < ALL | 大於最大值 / 小於最小值 |
Correlated Subquery 改寫
Correlated Subquery 中引用外層查詢的欄位,導致外層每處理一列就執行一次子查詢:
-- ❌ Correlated Subquery(效能差)
SELECT
e.employee_id, e.name,
(SELECT COUNT(*)
FROM orders o
WHERE o.employee_id = e.employee_id) AS order_count
FROM employees e;
-- 若 employees 有 10000 列,子查詢執行 10000 次!
改寫方式一:LEFT JOIN + GROUP BY
-- ✅ 效能佳
SELECT e.employee_id, e.name, COUNT(o.order_id) AS order_count
FROM employees e
LEFT JOIN orders o USING (employee_id)
GROUP BY e.employee_id, e.name;
改寫方式二:CTE 預先聚合
-- ✅ 語義更清晰
WITH order_counts AS (
SELECT employee_id, COUNT(*) AS order_count
FROM orders
GROUP BY employee_id
)
SELECT e.employee_id, e.name,
COALESCE(oc.order_count, 0) AS order_count
FROM employees e
LEFT JOIN order_counts oc USING (employee_id);
改寫方式三:Window Function 取代排名子查詢
-- ❌ 子查詢計算部門內薪資排名
SELECT e.name, e.salary,
(SELECT COUNT(*) + 1
FROM employees e2
WHERE e2.department_id = e.department_id
AND e2.salary > e.salary) AS rank_in_dept
FROM employees e;
-- ✅ Window Function(最佳方案)
SELECT name, salary,
RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) AS rank_in_dept
FROM employees;
可寫 CTE(WITH … INSERT/UPDATE/DELETE)
可寫 CTE 允許在 WITH 子句中執行 DML,並透過 RETURNING 傳遞結果:
-- INSERT 並立即使用返回的 ID
WITH inserted AS (
INSERT INTO customers (name, email)
VALUES ('新客戶', 'new@example.com')
RETURNING customer_id, name
)
INSERT INTO customer_audit (customer_id, action, action_time)
SELECT customer_id, 'CREATED', NOW()
FROM inserted;
-- 資料搬移:從一張表刪除,插入另一張表
WITH moved AS (
DELETE FROM orders
WHERE order_date < '2020-01-01'
RETURNING *
)
INSERT INTO orders_archive
SELECT * FROM moved;
-- UPDATE 並記錄變更
WITH salary_update AS (
UPDATE employees
SET salary = salary * 1.1
WHERE performance_rating = 'A'
RETURNING employee_id, name,
salary AS new_salary,
salary / 1.1 AS old_salary
)
INSERT INTO salary_history (employee_id, old_salary, new_salary, changed_at)
SELECT employee_id, old_salary, new_salary, NOW()
FROM salary_update;
重要特性:
- 同一
WITH語句中的所有 CTE 以相同快照執行,彼此看不到對方的修改 - 必須使用
RETURNING才能將 DML 結果傳遞給後續 CTE
子查詢執行策略
PostgreSQL 規劃器對子查詢有三種執行策略,可透過 EXPLAIN 觀察:
| 策略 | 行為 | 效能 |
|---|---|---|
| InitPlan | 非關聯子查詢,只執行一次,結果快取 | 最佳 |
| Hashed SubPlan | IN / = ANY 型,建 Hash Table + O(1) 查找 | 接近 Hash Join |
| SubPlan | 關聯子查詢,外層每列執行一次 | 最差(N 次) |
-- InitPlan 範例
SELECT * FROM employees
WHERE salary > (SELECT AVG(salary) FROM employees);
-- EXPLAIN 顯示:InitPlan 1 (returns $0)
-- SubPlan 範例(應改寫為 JOIN)
SELECT e.name,
(SELECT MAX(o.amount) FROM orders o
WHERE o.employee_id = e.employee_id) AS max_order
FROM employees e;
-- EXPLAIN 顯示:SubPlan 1 → 每列執行一次
版本演進
| 版本 | 重要特性 |
|---|---|
| PG 8.4 | 引入 CTE(WITH 子句)與遞迴 CTE |
| PG 9.1 | 可寫 CTE(WITH … INSERT/UPDATE/DELETE) |
| PG 12 | CTE 智慧型 Inline/Materialized 決策;MATERIALIZED / NOT MATERIALIZED 關鍵字 |
| PG 14 | 遞迴 CTE 的 CYCLE 與 SEARCH 子句(ISO SQL 標準) |
常見陷阱
CTE 被多次引用時的重複計算
-- PG12+ 若 CTE 被多次引用但規劃器選擇 Inline,可能重複計算
-- 計算昂貴的 CTE 應強制 MATERIALIZED
WITH expensive_stats AS MATERIALIZED (
SELECT department_id,
AVG(salary) AS avg_sal,
STDDEV(salary) AS std_sal
FROM employees
GROUP BY department_id
)
SELECT e.name, e.salary, es.avg_sal
FROM employees e
JOIN expensive_stats es USING (department_id) -- 第一次引用
WHERE e.salary > (
SELECT avg_sal + std_sal
FROM expensive_stats -- 第二次引用
WHERE department_id = e.department_id
);
-- MATERIALIZED 確保只計算一次
遞迴 CTE 中 UNION vs UNION ALL
-- UNION ALL:允許重複列,效能佳(推薦)
-- UNION:每步去除重複,效能差但可防止某些類型的無窮迴圈
-- 通常搭配路徑陣列偵測 + UNION ALL 是最佳組合
總結
CTE 與子查詢 是 PostgreSQL 查詢組合的核心工具:
- 非遞迴 CTE 提升查詢可讀性,PG12+ 智慧型決策避免優化障壁
- 遞迴 CTE 處理樹狀結構、圖遍歷、BOM 展開等遞迴問題
- CYCLE / SEARCH(PG14+)提供原生循環偵測與遍歷順序控制
- 可寫 CTE 在單一語句中完成多步驟 DML 操作
- EXISTS 是最安全的存在性檢查;NOT IN 遇 NULL 會失效,改用 NOT EXISTS
- Correlated Subquery 效能極差,應改寫為 JOIN 或 Window Function
下一篇,我們將深入探討 JSON 與 JSONB 操作——PostgreSQL 的半結構化資料處理能力。