進階雜湊技術 — Consistent Hashing、Cuckoo Hashing 與 Perfect Hashing | 資料結構與演算法
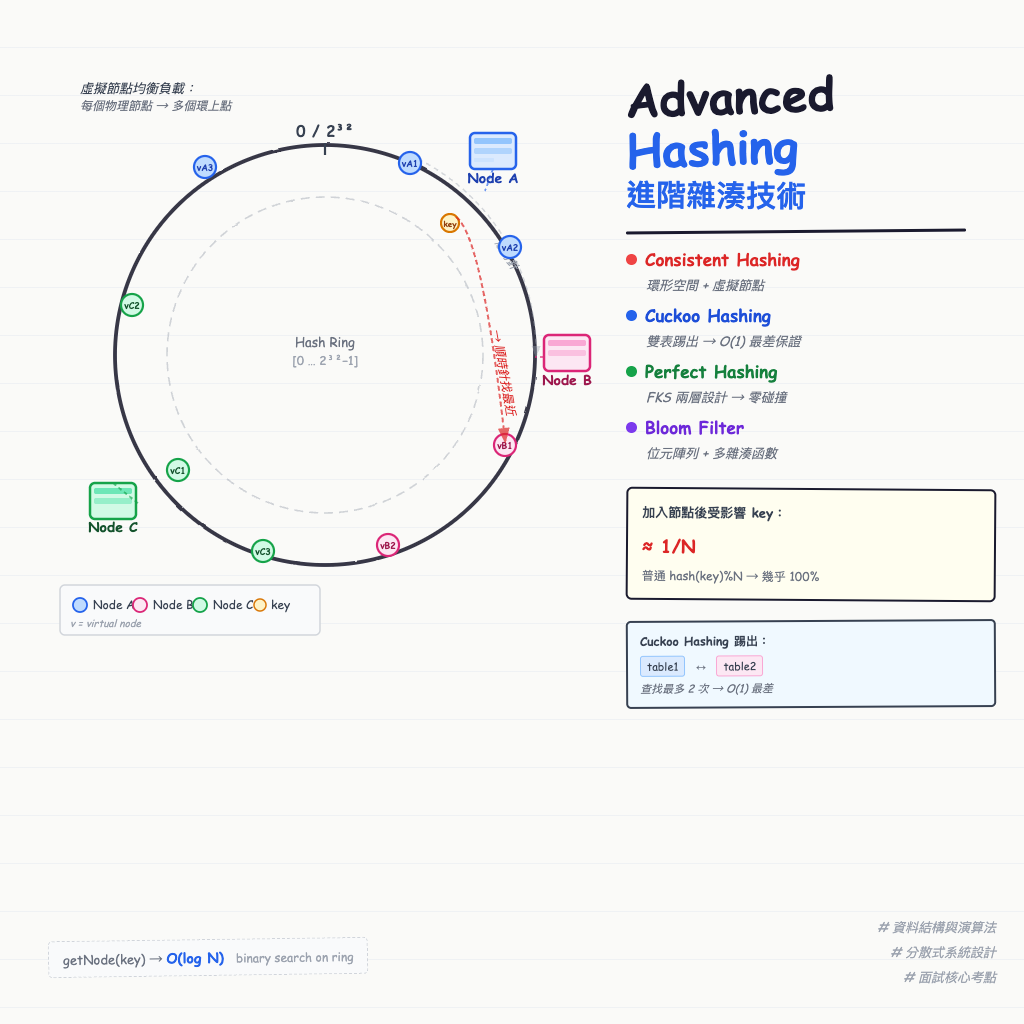
進階雜湊技術(Advanced Hashing)是基礎雜湊表向特殊場景的延伸:Consistent Hashing 解決分散式節點增減時幾乎所有 key 都需要重新映射的問題;Cuckoo Hashing 透過雙表踢出機制,讓查詢在最壞情況下也只需兩次存取;Perfect Hashing 則用兩層設計徹底消除碰撞。這些技術是 Memcached、Redis Cluster 與系統設計面試的核心考點。
前言
想像你在管理一個分散式快取集群,有三台伺服器。用最簡單的方式分片:server = hash(key) % 3。運作正常——直到你需要擴容,加入第四台伺服器。
一旦 N 從 3 變成 4,hash(key) % 3 的結果與 hash(key) % 4 幾乎完全不同。你的 99% 快取瞬間失效,所有請求直接打到資料庫,造成 Cache Stampede(快取雪崩)。Facebook、Twitter 的早期事故,有不少就是這樣發生的。
Consistent Hashing(一致性雜湊) 正是為了解決這個問題而設計——增減節點時,平均只有 1/N 的 key 需要遷移。
讀完這篇文章,你將學會:
- 理解一致性雜湊環(Hash Ring)的運作原理與虛擬節點設計
- 掌握 Cuckoo Hashing 的雙表踢出機制與 O(1) 最壞保證
- 了解 Perfect Hashing(FKS)的兩層設計如何消除碰撞
- 實作 Bloom Filter 並分析假陽性率的數學背景
- 認識 Count-Min Sketch 與 HyperLogLog 在大數據中的應用
- 在系統設計面試中正確選用合適的雜湊技術
一致性雜湊(Consistent Hashing)
核心思想:環形空間
Consistent Hashing 的關鍵洞見是:把雜湊空間想像成一個環,而不是一條線。
- 建立一個虛擬環(Hash Ring),空間為
[0, 2³²-1],首尾相連 - 每台伺服器(節點)經雜湊後映射到環上的某個點
- 每個 key 也映射到環上,沿順時針方向找到的第一個節點就是負責節點
- 新增或移除節點時,只有相鄰區間的 key 受影響
Hash Ring(0 ─ 2³² - 1,首尾相連成環):
0 / 2³²
│
Node A (hash = 3億)
╱───────┤
╱ │
Node C ← │ → Node B
(hash=9億) ───┼─── (hash=6億)
╲ │ ╱
╲ │ ╱
╲│╱
│
hash(key1)=4億 → 順時針 → 找到 Node B(6億)✓
hash(key2)=8億 → 順時針 → 找到 Node C(9億)✓
hash(key3)=10億 → 順時針 → 繞回 Node A(3億)✓
新增 Node D(hash=7.5億):
→ 只有原本 Node B → Node C 之間的 key 需要重新映射
→ 受影響比例:約 1/4(新增後共 4 個節點)
→ 普通取模(% N):幾乎 100% 的 key 都需要重新映射
虛擬節點解決負載不均
單一節點只有一個環上位置時,偶爾會出現某台伺服器負責 75% 的 key,而另一台只負責 5% 的情況。虛擬節點(Virtual Nodes) 解決了這個問題:
每個物理節點映射到環上的多個點(通常 100-200 個):
Node A:hash("NodeA#0"), hash("NodeA#1"), ..., hash("NodeA#149")
Node B:hash("NodeB#0"), hash("NodeB#1"), ..., hash("NodeB#149")
實際效果:各節點負責的 key 數量趨近 total_keys / N
虛擬節點越多,分布越均勻,但記憶體占用也越高
TypeScript 完整實作
// Consistent Hashing Ring — 完整實作(含虛擬節點)
// 使用 FNV-1a 雜湊函數,生產環境建議換成 MurmurHash3 或 xxHash
function hash32(str: string): number {
let h = 2166136261; // FNV-1a 初始值
for (let i = 0; i < str.length; i++) {
h ^= str.charCodeAt(i);
h = Math.imul(h, 16777619); // FNV prime
h >>>= 0; // 轉為無符號 32-bit
}
return h;
}
interface RingEntry {
hash: number;
nodeId: string; // 物理節點 ID
virtualId: string; // 虛擬節點 ID("nodeId#i")
}
class ConsistentHashRing {
private ring: RingEntry[]; // 按 hash 排序的虛擬節點列表
private readonly virtualNodesPerServer: number;
constructor(virtualNodesPerServer: number = 150) {
this.ring = [];
this.virtualNodesPerServer = virtualNodesPerServer;
}
// 新增節點:O(V log N),V=虛擬節點數,N=環上節點總數
addNode(nodeId: string): void {
for (let i = 0; i < this.virtualNodesPerServer; i++) {
const virtualId = `${nodeId}#${i}`;
const h = hash32(virtualId);
const entry: RingEntry = { hash: h, nodeId, virtualId };
const pos = this.lowerBound(h);
this.ring.splice(pos, 0, entry); // 維持排序插入
}
}
// 移除節點:O(V log N)
removeNode(nodeId: string): void {
this.ring = this.ring.filter((entry) => entry.nodeId !== nodeId);
// 注意:必須移除所有虛擬節點,只移除部分會造成路由錯誤
}
// 查找 key 對應的節點:O(log N)
getNode(key: string): string | null {
if (this.ring.length === 0) return null;
const h = hash32(key);
const pos = this.lowerBound(h);
const idx = pos < this.ring.length ? pos : 0; // 繞回環的開頭
return this.ring[idx].nodeId;
}
// 查找 key 對應的 N 個節點(Replication Factor)
getNodes(key: string, count: number): string[] {
if (this.ring.length === 0) return [];
const h = hash32(key);
let pos = this.lowerBound(h);
const result: string[] = [];
const seen = new Set<string>();
for (let i = 0; i < this.ring.length && result.length < count; i++) {
const idx = (pos + i) % this.ring.length;
const nodeId = this.ring[idx].nodeId;
if (!seen.has(nodeId)) {
seen.add(nodeId);
result.push(nodeId);
}
}
return result;
}
// 二元搜尋:找到第一個 hash >= target 的位置
private lowerBound(target: number): number {
let lo = 0;
let hi = this.ring.length;
while (lo < hi) {
const mid = (lo + hi) >>> 1;
if (this.ring[mid].hash < target) {
lo = mid + 1;
} else {
hi = mid;
}
}
return lo;
}
// 負載分析
getLoadDistribution(): Map<string, number> {
const dist = new Map<string, number>();
for (const entry of this.ring) {
dist.set(entry.nodeId, (dist.get(entry.nodeId) ?? 0) + 1);
}
return dist;
}
}
// 模擬分散式快取集群
const ring = new ConsistentHashRing(150);
ring.addNode("cache-1");
ring.addNode("cache-2");
ring.addNode("cache-3");
console.log(ring.getNode("user:1001")); // 輸出:"cache-2"(穩定路由)
console.log(ring.getNodes("product:500", 2)); // 輸出:["cache-3", "cache-1"](副本)
ring.addNode("cache-4"); // 擴容:只影響約 1/4 的 key
console.log(ring.getNode("user:1001")); // 可能不變,也可能路由到 cache-4
Cuckoo Hashing — O(1) 最壞查詢
踢出機制圖解
Cuckoo Hashing 名稱來自布穀鳥(Cuckoo)把蛋放入別人巢中的行為。核心設計:使用兩張表和兩個雜湊函數,每個 key 只可能在 table1[h1(key)] 或 table2[h2(key)] 這兩個位置之一。
初始狀態:
table1: [ A ][ B ][ _ ]
table2: [ _ ][ C ][ _ ]
插入 D,h1(D)=0,但 table1[0] 已被 A 佔用:
→ 踢出 A,將 D 放入 table1[0]
table1: [ D ][ B ][ _ ]
被踢出的 A 嘗試 table2[h2(A)]=1,已被 C 佔用:
→ 踢出 C,將 A 放入 table2[1]
table2: [ _ ][ A ][ _ ]
被踢出的 C 嘗試 table1[h1(C)]=2(空位):
→ C 直接放入
table1: [ D ][ B ][ C ]
最終狀態:
table1: [ D ][ B ][ C ]
table2: [ _ ][ A ][ _ ]
查找 key:只需查 table1[h1(key)] 或 table2[h2(key)],最多 2 次 → O(1) 最壞
TypeScript 實作
// Cuckoo Hashing — 保證 O(1) 最壞查找
const CUCKOO_MAX_EVICTIONS = 500; // 超過則觸發 Rehash
class CuckooHashTable<V> {
private table1: Array<{ key: string; value: V } | null>;
private table2: Array<{ key: string; value: V } | null>;
private capacity: number;
private size_: number;
constructor(initialCapacity: number = 64) {
this.capacity = initialCapacity;
this.size_ = 0;
this.table1 = new Array(this.capacity).fill(null);
this.table2 = new Array(this.capacity).fill(null);
}
// 雜湊函數1(FNV-1a)
private h1(key: string): number {
let h = 2166136261;
for (let i = 0; i < key.length; i++) {
h ^= key.charCodeAt(i);
h = Math.imul(h, 16777619);
}
return (h >>> 0) % this.capacity;
}
// 雜湊函數2(djb2 變體,必須與 h1 獨立)
private h2(key: string): number {
let h = 5381;
for (let i = 0; i < key.length; i++) {
h = Math.imul(h, 33) ^ key.charCodeAt(i);
}
return (h >>> 0) % this.capacity;
}
// 查找:O(1) 最壞(只需看兩個位置)
get(key: string): V | undefined {
const pos1 = this.h1(key);
if (this.table1[pos1]?.key === key) return this.table1[pos1]!.value;
const pos2 = this.h2(key);
if (this.table2[pos2]?.key === key) return this.table2[pos2]!.value;
return undefined;
}
has(key: string): boolean {
return this.get(key) !== undefined;
}
// 插入:O(1) amortized
set(key: string, value: V): boolean {
// 先檢查是否已存在(更新)
const pos1 = this.h1(key);
if (this.table1[pos1]?.key === key) {
this.table1[pos1] = { key, value };
return true;
}
const pos2 = this.h2(key);
if (this.table2[pos2]?.key === key) {
this.table2[pos2] = { key, value };
return true;
}
return this.insertWithEviction(key, value);
}
private insertWithEviction(key: string, value: V): boolean {
let currentKey = key;
let currentValue = value;
let useTable1 = true;
for (let evictions = 0; evictions < CUCKOO_MAX_EVICTIONS; evictions++) {
if (useTable1) {
const pos = this.h1(currentKey);
const displaced = this.table1[pos];
this.table1[pos] = { key: currentKey, value: currentValue };
if (displaced === null) {
this.size_++;
return true;
}
currentKey = displaced.key;
currentValue = displaced.value;
} else {
const pos = this.h2(currentKey);
const displaced = this.table2[pos];
this.table2[pos] = { key: currentKey, value: currentValue };
if (displaced === null) {
this.size_++;
return true;
}
currentKey = displaced.key;
currentValue = displaced.value;
}
useTable1 = !useTable1; // 交替使用兩張表
}
// 超過最大踢出次數,表示可能形成循環,觸發 Rehash
this.rehash();
return this.set(currentKey, currentValue);
}
// 刪除:O(1)
delete(key: string): boolean {
const pos1 = this.h1(key);
if (this.table1[pos1]?.key === key) {
this.table1[pos1] = null;
this.size_--;
return true;
}
const pos2 = this.h2(key);
if (this.table2[pos2]?.key === key) {
this.table2[pos2] = null;
this.size_--;
return true;
}
return false;
}
private rehash(): void {
const oldTable1 = this.table1;
const oldTable2 = this.table2;
this.capacity *= 2;
this.table1 = new Array(this.capacity).fill(null);
this.table2 = new Array(this.capacity).fill(null);
this.size_ = 0;
for (const entry of [...oldTable1, ...oldTable2]) {
if (entry !== null) this.set(entry.key, entry.value);
}
}
get size(): number { return this.size_; }
get loadFactor(): number { return this.size_ / (this.capacity * 2); }
}
// 使用範例
const cuckoo = new CuckooHashTable<number>();
cuckoo.set("apple", 1);
cuckoo.set("banana", 2);
cuckoo.set("cherry", 3);
console.log(cuckoo.get("banana")); // 輸出:2
console.log(cuckoo.has("cherry")); // 輸出:true
console.log(cuckoo.delete("apple")); // 輸出:true
console.log(cuckoo.get("apple")); // 輸出:undefined
console.log(`負載因子:${cuckoo.loadFactor.toFixed(3)}`);
Perfect Hashing — 零碰撞靜態設計
Perfect Hashing 保證查詢在最壞情況下也是 O(1),且沒有碰撞。代價是它只適用於靜態集合(編譯時已知所有鍵值)。
FKS 兩層架構
Level 1(普通雜湊):
→ 將 n 個鍵值映射到 m 個桶,桶內可能有碰撞
Level 2(桶內二次雜湊):
→ 對每個桶使用獨立的雜湊函數
→ 桶的大小設為「桶內元素數量的平方」
→ 數學保證:此大小下必然存在無碰撞的雜湊函數
性質:
→ 查找:O(1) 最壞(兩次雜湊計算)
→ 空間:O(n)(雖然每個桶是平方大小,但總空間仍為線性)
→ 建構:O(n) 期望(需要嘗試不同的雜湊函數)
→ 限制:插入或刪除都需要完全重建
// Perfect Hashing(FKS Scheme)— 靜態集合查找
class PerfectHashTable {
private level1Size: number;
private level1Hash: (key: string) => number;
// 第二層:每個桶有自己的雜湊函數和儲存空間
private level2: Array<{
fn: (key: string) => number;
storage: Array<string | null>;
}>;
constructor(keys: string[]) {
const n = keys.length;
this.level1Size = n; // 第一層大小 = n
// 找一個第一層雜湊函數使碰撞數最小
this.level1Hash = this.buildLevel1Hash(keys);
// 依第一層分配到各桶
const buckets: string[][] = Array.from({ length: n }, () => []);
for (const key of keys) {
buckets[this.level1Hash(key)].push(key);
}
// 對每個桶建立第二層(無碰撞)
this.level2 = buckets.map((bucket) => {
const size = bucket.length * bucket.length; // 平方大小
const storage = new Array(Math.max(size, 1)).fill(null);
const fn = this.buildLevel2Hash(bucket, storage);
return { fn, storage };
});
}
get(key: string): boolean {
const b = this.level1Hash(key);
if (b >= this.level2.length) return false;
const { fn, storage } = this.level2[b];
const pos = fn(key);
return storage[pos] === key;
}
private buildLevel1Hash(keys: string[]): (key: string) => number {
// 實際實作中會嘗試多個隨機種子找最少碰撞的
const n = keys.length;
return (key: string) => {
let h = 2166136261;
for (let i = 0; i < key.length; i++) {
h ^= key.charCodeAt(i);
h = Math.imul(h, 16777619);
}
return (h >>> 0) % n;
};
}
private buildLevel2Hash(
bucket: string[],
storage: Array<string | null>
): (key: string) => number {
const size = storage.length;
// 嘗試不同種子,直到找到無碰撞的雜湊函數
for (let seed = 1; seed < 1000; seed++) {
const fn = (key: string) => {
let h = seed;
for (let i = 0; i < key.length; i++) {
h ^= key.charCodeAt(i);
h = Math.imul(h, 16777619 + seed);
}
return (h >>> 0) % size;
};
const slots = new Set<number>();
let collision = false;
for (const key of bucket) {
const pos = fn(key);
if (slots.has(pos)) { collision = true; break; }
slots.add(pos);
}
if (!collision) {
// 無碰撞:填入 storage 並回傳此函數
for (const key of bucket) {
storage[fn(key)] = key;
}
return fn;
}
}
// 極罕見情況:fallback(不應發生在正確實作中)
return () => 0;
}
}
// 使用範例:編譯器關鍵字查找
const keywords = ["if", "else", "for", "while", "return", "const", "let", "var", "class", "function"];
const keywordSet = new PerfectHashTable(keywords);
console.log(keywordSet.get("if")); // 輸出:true
console.log(keywordSet.get("return")); // 輸出:true
console.log(keywordSet.get("myVar")); // 輸出:false
Bloom Filter — 空間高效的集合存在性查詢
Bloom Filter 是一種機率性資料結構,用 m 位元的陣列加上 k 個雜湊函數,空間效率極高,但可能出現假陽性(False Positive),不存在的元素可能被誤判為存在;存在的元素則一定能被正確識別(不會有假陰性)。
插入 "apple"(k=3 個雜湊函數):
h1("apple")=2 → 位元 2 設為 1
h2("apple")=5 → 位元 5 設為 1
h3("apple")=9 → 位元 9 設為 1
查詢 "apple":
位元 2=1 ✓, 位元 5=1 ✓, 位元 9=1 ✓ → 存在(正確)
查詢 "grape":
h1("grape")=2=1, h2("grape")=5=1, h3("grape")=7=0 → 不存在(正確)
查詢 "mango":
h1("mango")=2=1, h2("mango")=5=1, h3("mango")=9=1 → 「存在」(假陽性!)
→ "mango" 從未被插入,但三個位元碰巧都被其他元素設為 1
假陽性率數學分析
假陽性率 p ≈ (1 - e^(-kn/m))^k
其中:
m = 位元陣列大小
n = 已插入的元素數量
k = 雜湊函數數量
最佳 k 值(使假陽性率最小):k = (m/n) * ln(2) ≈ 0.693 * (m/n)
實際案例(n=10,000,期望假陽性率 1%):
→ m ≈ 95,851 位元(約 12KB,遠小於存完整字串的空間)
→ k ≈ 7 個雜湊函數
// Bloom Filter 完整實作
class BloomFilter {
private bits: Uint8Array;
private readonly m: number; // 位元數
private readonly k: number; // 雜湊函數數量
private count: number; // 已插入元素數
constructor(expectedElements: number, falsePositiveRate: number = 0.01) {
// 根據期望元素數和假陽性率計算最佳參數
this.m = Math.ceil(
(-expectedElements * Math.log(falsePositiveRate)) / (Math.LN2 ** 2)
);
this.k = Math.max(1, Math.round((this.m / expectedElements) * Math.LN2));
this.bits = new Uint8Array(Math.ceil(this.m / 8));
this.count = 0;
console.log(`Bloom Filter: m=${this.m} bits, k=${this.k} hash functions`);
}
// 使用種子產生不同的雜湊函數(Kirsch-Mitzenmacher 方法)
private hash(item: string, seed: number): number {
// 基礎雜湊 h1 和 h2
let h1 = 2166136261;
let h2 = 5381;
for (let i = 0; i < item.length; i++) {
h1 ^= item.charCodeAt(i);
h1 = Math.imul(h1, 16777619);
h2 = Math.imul(h2, 33) ^ item.charCodeAt(i);
}
// 第 i 個雜湊 = h1 + i * h2(只需兩個基礎雜湊即可模擬 k 個)
return ((h1 >>> 0) + seed * (h2 >>> 0)) % this.m;
}
private setBit(pos: number): void {
this.bits[Math.floor(pos / 8)] |= (1 << (pos % 8));
}
private getBit(pos: number): boolean {
return (this.bits[Math.floor(pos / 8)] & (1 << (pos % 8))) !== 0;
}
add(item: string): void {
for (let i = 0; i < this.k; i++) {
this.setBit(this.hash(item, i));
}
this.count++;
}
// 查詢:可能有假陽性,但不會有假陰性
mightContain(item: string): boolean {
for (let i = 0; i < this.k; i++) {
if (!this.getBit(this.hash(item, i))) return false;
}
return true; // 可能存在(有小概率假陽性)
}
get estimatedFalsePositiveRate(): number {
const ratio = 1 - Math.exp(-this.k * this.count / this.m);
return ratio ** this.k;
}
get bitsUsed(): number { return this.m; }
get numHashFunctions(): number { return this.k; }
}
// 使用範例:URL 去重(爬蟲)
const filter = new BloomFilter(100_000, 0.01); // 10 萬 URL,1% 假陽性率
// 輸出:Bloom Filter: m=958506 bits, k=7 hash functions(約 117KB)
filter.add("https://example.com/page1");
filter.add("https://example.com/page2");
console.log(filter.mightContain("https://example.com/page1")); // 輸出:true(確定存在)
console.log(filter.mightContain("https://example.com/page99")); // 輸出:false(不存在)
console.log(`預期假陽性率:${(filter.estimatedFalsePositiveRate * 100).toFixed(4)}%`);
C++ 對照:ConsistentHashRing
#include <map>
#include <string>
#include <vector>
#include <algorithm>
// 使用 std::map(底層紅黑樹,自動有序)實作一致性雜湊
// 相較 TypeScript 的 sorted array,C++ 的 std::map::lower_bound 更高效
uint32_t hashString(const std::string& s) {
uint32_t h = 2166136261u;
for (unsigned char c : s) {
h ^= c;
h *= 16777619u;
}
return h;
}
class ConsistentHashRing {
private:
std::map<uint32_t, std::string> ring; // 自動按 hash 排序
int virtualNodesPerServer;
public:
explicit ConsistentHashRing(int virtualNodes = 150)
: virtualNodesPerServer(virtualNodes) {}
// 新增節點:O(V log N)
void addNode(const std::string& nodeId) {
for (int i = 0; i < virtualNodesPerServer; i++) {
const std::string virtualId = nodeId + "#" + std::to_string(i);
ring[hashString(virtualId)] = nodeId;
}
}
// 移除節點:O(V log N)
void removeNode(const std::string& nodeId) {
for (int i = 0; i < virtualNodesPerServer; i++) {
const std::string virtualId = nodeId + "#" + std::to_string(i);
ring.erase(hashString(virtualId));
}
}
// 查找 key 對應節點:O(log N)
std::string getNode(const std::string& key) const {
if (ring.empty()) return "";
auto it = ring.lower_bound(hashString(key)); // 找 >= hash 的第一個節點
if (it == ring.end()) it = ring.begin(); // 繞回環的開頭
return it->second;
}
// 查找 N 個節點(副本)
std::vector<std::string> getNodes(const std::string& key, int count) const {
if (ring.empty()) return {};
auto it = ring.lower_bound(hashString(key));
std::vector<std::string> result;
std::vector<std::string> seen;
auto startIt = it;
bool wrapped = false;
while (static_cast<int>(result.size()) < count) {
if (it == ring.end()) {
if (wrapped) break;
it = ring.begin();
wrapped = true;
}
if (wrapped && it == startIt) break;
const std::string& nodeId = it->second;
if (std::find(seen.begin(), seen.end(), nodeId) == seen.end()) {
seen.push_back(nodeId);
result.push_back(nodeId);
}
++it;
}
return result;
}
};
// 使用範例
// ConsistentHashRing ring(150);
// ring.addNode("cache-server-1");
// ring.addNode("cache-server-2");
// ring.addNode("cache-server-3");
// std::string server = ring.getNode("user:1001"); // 確定性路由
複雜度分析表
| 技術 | 查找(最壞) | 查找(平均) | 插入 | 刪除 | 適用場景 |
|---|---|---|---|---|---|
| Consistent Hashing | O(log N) | O(log N) | O(V log N) | O(V log N) | 分散式快取節點分配 |
| Cuckoo Hashing | O(1) | O(1) | O(1) amortized | O(1) | 需要 O(1) 最壞保證 |
| Perfect Hashing | O(1) | O(1) | O(n) 重建 | O(n) 重建 | 靜態集合查找 |
| Bloom Filter | N/A | O(k) | O(k) | 不支援 | 集合存在性(允許假陽性) |
| Robin Hood Hash | O(log n) | O(1) | O(1) amortized | O(1) | 高負載因子場景 |
N = 環上虛擬節點總數,V = 每個節點的虛擬節點數,k = 雜湊函數數量
變體與延伸
Counting Bloom Filter — 支援刪除
標準 Bloom Filter 無法刪除元素(設為 1 的位元無法確定是哪個元素設置的)。Counting Bloom Filter 將每個位元升級為計數器(通常 4-bit):
// Counting Bloom Filter — 支援刪除操作
class CountingBloomFilter {
private counters: Uint8Array; // 4-bit 計數器,每個 byte 存兩個
constructor(private readonly m: number, private readonly k: number) {
this.counters = new Uint8Array(Math.ceil(m / 2)); // 每 4-bit 一個計數器
}
private increment(pos: number): void {
const byteIdx = Math.floor(pos / 2);
const isHigh = pos % 2 === 1;
const current = isHigh
? (this.counters[byteIdx] >> 4) & 0xF
: this.counters[byteIdx] & 0xF;
if (current < 15) { // 防止 4-bit 溢位
if (isHigh) this.counters[byteIdx] += 0x10;
else this.counters[byteIdx]++;
}
}
private decrement(pos: number): void {
const byteIdx = Math.floor(pos / 2);
const isHigh = pos % 2 === 1;
const current = isHigh
? (this.counters[byteIdx] >> 4) & 0xF
: this.counters[byteIdx] & 0xF;
if (current > 0) {
if (isHigh) this.counters[byteIdx] -= 0x10;
else this.counters[byteIdx]--;
}
}
private getCount(pos: number): number {
const byteIdx = Math.floor(pos / 2);
const isHigh = pos % 2 === 1;
return isHigh
? (this.counters[byteIdx] >> 4) & 0xF
: this.counters[byteIdx] & 0xF;
}
private hash(item: string, seed: number): number {
let h1 = 2166136261, h2 = 5381;
for (let i = 0; i < item.length; i++) {
h1 ^= item.charCodeAt(i); h1 = Math.imul(h1, 16777619);
h2 = Math.imul(h2, 33) ^ item.charCodeAt(i);
}
return ((h1 >>> 0) + seed * (h2 >>> 0)) % this.m;
}
add(item: string): void {
for (let i = 0; i < this.k; i++) this.increment(this.hash(item, i));
}
// 刪除:前提是元素確實存在(否則計數器可能出現錯誤)
remove(item: string): void {
for (let i = 0; i < this.k; i++) this.decrement(this.hash(item, i));
}
mightContain(item: string): boolean {
for (let i = 0; i < this.k; i++) {
if (this.getCount(this.hash(item, i)) === 0) return false;
}
return true;
}
}
Count-Min Sketch — 高頻元素估計
當你需要的不是「是否存在」,而是「出現了幾次」,Count-Min Sketch 登場。用 d × w 的二維計數器陣列,每個元素透過 d 個雜湊函數映射到每列的一個位置,取各列計數的最小值作為估計:
// Count-Min Sketch — 頻率估計(允許過估,不會低估)
class CountMinSketch {
private table: number[][];
private readonly d: number; // 列數(雜湊函數數量)
private readonly w: number; // 欄數(每列的計數器數量)
constructor(epsilon: number = 0.01, delta: number = 0.01) {
// d = ceil(ln(1/delta)),w = ceil(e/epsilon)
this.d = Math.ceil(Math.log(1 / delta));
this.w = Math.ceil(Math.E / epsilon);
this.table = Array.from({ length: this.d }, () => new Array(this.w).fill(0));
}
private hash(item: string, row: number): number {
let h = (row + 1) * 2654435761;
for (let i = 0; i < item.length; i++) {
h = Math.imul(h ^ item.charCodeAt(i), 2246822519);
}
return (h >>> 0) % this.w;
}
// 增加計數
update(item: string, count: number = 1): void {
for (let i = 0; i < this.d; i++) {
this.table[i][this.hash(item, i)] += count;
}
}
// 估計頻率:取各列最小值(保證不低估)
estimate(item: string): number {
let min = Infinity;
for (let i = 0; i < this.d; i++) {
min = Math.min(min, this.table[i][this.hash(item, i)]);
}
return min;
}
}
// 使用範例:統計網路流量中各 IP 的封包數
const sketch = new CountMinSketch(0.01, 0.01); // 誤差 1%,失敗機率 1%
sketch.update("192.168.1.1", 100);
sketch.update("10.0.0.1", 50);
sketch.update("192.168.1.1", 200);
console.log(sketch.estimate("192.168.1.1")); // 輸出:約 300(可能略有過估)
console.log(sketch.estimate("10.0.0.1")); // 輸出:約 50
HyperLogLog — 基數估計
需要知道有多少不重複元素(基數)?HyperLogLog 只用 1.5KB 的記憶體就能估計數十億個不重複元素,誤差僅約 2%。Redis 的 PFADD/PFCOUNT 指令就是 HyperLogLog 的實作。
// HyperLogLog — 基數(不重複元素數量)估計
class HyperLogLog {
private readonly m: number; // 桶數(2^b)
private readonly b: number; // 位元數
private registers: Uint8Array; // 每個桶儲存最大前導零數+1
constructor(b: number = 10) { // b=10 → m=1024 桶,誤差約 3.2%
this.b = b;
this.m = 1 << b; // 輸出:1024
this.registers = new Uint8Array(this.m);
}
private hash(item: string): number {
let h = 2166136261;
for (let i = 0; i < item.length; i++) {
h ^= item.charCodeAt(i);
h = Math.imul(h, 16777619);
}
return h >>> 0;
}
// 計算前導零數量(+1)
private leadingZeros(hash: number, skip: number): number {
let mask = 1 << (31 - skip);
let count = 1;
while (mask > 0 && (hash & mask) === 0) {
count++;
mask >>= 1;
}
return count;
}
add(item: string): void {
const hash = this.hash(item);
const bucket = hash >>> (32 - this.b); // 用前 b 位決定桶
const remaining = hash & ((1 << (32 - this.b)) - 1); // 剩餘位
const zeros = this.leadingZeros(remaining, 0);
this.registers[bucket] = Math.max(this.registers[bucket], zeros);
}
// 估計基數
count(): number {
const alpha = 0.7213 / (1 + 1.079 / this.m); // 修正係數
let sum = 0;
for (let i = 0; i < this.m; i++) {
sum += 2 ** -this.registers[i];
}
let estimate = alpha * this.m * this.m / sum;
// 小基數修正
if (estimate <= 2.5 * this.m) {
const zeros = this.registers.filter((r) => r === 0).length;
if (zeros > 0) estimate = this.m * Math.log(this.m / zeros);
}
return Math.round(estimate);
}
}
// 使用範例:統計獨立訪客數(UV)
const hll = new HyperLogLog(10); // 約 1KB 記憶體
const users = ["alice", "bob", "charlie", "alice", "bob", "diana"]; // 實際 4 人
for (const user of users) hll.add(user);
console.log(`估計不重複用戶數:${hll.count()}`); // 輸出:約 4(允許小誤差)
面試考點
系統設計:分散式快取設計
問題: 設計一個可水平擴展的分散式快取系統(類 Memcached)。
回答要點:
分片策略選擇
- 普通取模(
hash(key) % N):實作最簡單,但擴容時幾乎所有 key 需要遷移,造成快取雪崩 - Consistent Hashing(推薦):擴容只影響
1/N的 key,搭配虛擬節點確保負載均衡
- 普通取模(
虛擬節點數量
- 太少(< 50):節點分布不均,某台伺服器可能承擔 30%+ 的流量
- 太多(> 300):記憶體占用增加,新增節點時的計算成本上升
- 推薦 100-200 個:在均衡性和效率間取得平衡
副本策略(Replication)
getNodes(key, replicationFactor)取順時針最近的 N 個不同物理節點- 讀寫可分為一致性優先(所有副本一致)或可用性優先(最終一致性)
節點故障處理
- 心跳檢測:定期偵測節點狀態
- 故障轉移:
removeNode()後,原節點負責的 key 自動路由到下一個節點
// 面試實作:帶副本的分散式快取
class DistributedCache {
private ring: ConsistentHashRing;
private stores: Map<string, Map<string, string>>;
private readonly replicationFactor: number;
constructor(servers: string[], replicationFactor: number = 2) {
this.ring = new ConsistentHashRing(150);
this.stores = new Map();
this.replicationFactor = replicationFactor;
for (const server of servers) {
this.ring.addNode(server);
this.stores.set(server, new Map());
}
}
set(key: string, value: string): void {
const servers = this.ring.getNodes(key, this.replicationFactor);
for (const server of servers) {
this.stores.get(server)?.set(key, value);
}
}
get(key: string): string | null {
const servers = this.ring.getNodes(key, this.replicationFactor);
for (const server of servers) {
const val = this.stores.get(server)?.get(key);
if (val !== undefined) return val;
}
return null;
}
addServer(server: string): void {
this.ring.addNode(server);
this.stores.set(server, new Map());
// 實際系統需要將受影響的 key 從舊節點遷移到新節點
}
removeServer(server: string): void {
this.ring.removeNode(server);
this.stores.delete(server);
// 實際系統需要從副本重新補充受影響 key 的副本
}
}
去重系統設計
問題: 設計一個能高效判斷 URL 是否已被爬取的系統(數十億 URL 規模)。
| 方案 | 記憶體 | 假陽性 | 刪除支援 | 適用場景 |
|---|---|---|---|---|
| HashSet | 極大(100+ GB) | 無 | 支援 | 小規模(< 1 億) |
| Bloom Filter | 極小(~1GB/10億) | 有(可控) | 不支援 | 大規模,允許極少誤判 |
| Counting Bloom Filter | 較小(~4GB/10億) | 有(可控) | 支援 | 需要刪除操作 |
| Redis + HyperLogLog | 小(~1.5KB/集合) | 有 | 不精確 | 只需計數,不需精確判斷 |
推薦架構:
- 第一層:Bloom Filter(快速預判,99%+ 命中)
- 第二層:持久化 DB 或 Redis(最終確認)
LeetCode 練習
| # | 題目 | 難度 | 核心技巧 |
|---|---|---|---|
| 705 | Design HashSet | Easy | 雜湊表基礎 |
| 706 | Design HashMap | Easy | 雜湊表基礎 |
| 187 | Repeated DNA Sequences | Medium | Rolling Hash 滑動視窗去重 |
| 1044 | Longest Duplicate Substring | Hard | Binary Search + Rolling Hash |
| 355 | Design Twitter | Medium | 雜湊表 + 系統設計 |
1044 — Longest Duplicate Substring 解題思路
問題: 找出字串 s 中最長的重複子字串(允許重疊)。
思路:Binary Search + Rolling Hash(Rabin-Karp)
- 二元搜尋長度
L:若長度L的重複子字串存在,則長度L-1也一定存在(單調性) - Rolling Hash 驗證長度
L:計算所有長度L的子字串雜湊,若有重複則找到答案
// 1044. Longest Duplicate Substring
function longestDupSubstring(s: string): string {
const n = s.length;
const MOD1 = 1_000_000_007n;
const MOD2 = 998_244_353n;
const BASE1 = 31n;
const BASE2 = 37n;
const codes = Array.from(s, (c) => BigInt(c.charCodeAt(0) - 96));
// 檢查是否有長度 len 的重複子字串
function check(len: number): number {
let pow1 = 1n, pow2 = 1n;
for (let i = 0; i < len; i++) {
pow1 = (pow1 * BASE1) % MOD1;
pow2 = (pow2 * BASE2) % MOD2;
}
let h1 = 0n, h2 = 0n;
for (let i = 0; i < len; i++) {
h1 = (h1 * BASE1 + codes[i]) % MOD1;
h2 = (h2 * BASE2 + codes[i]) % MOD2;
}
const seen = new Map<string, number>();
seen.set(`${h1},${h2}`, 0);
for (let i = 1; i <= n - len; i++) {
// Rolling Hash:移除最左字符,加入新字符(O(1) 更新)
h1 = (h1 * BASE1 - codes[i - 1] * pow1 % MOD1 + MOD1 + codes[i + len - 1]) % MOD1;
h2 = (h2 * BASE2 - codes[i - 1] * pow2 % MOD2 + MOD2 + codes[i + len - 1]) % MOD2;
const key = `${h1},${h2}`;
if (seen.has(key)) {
const prevStart = seen.get(key)!;
// 雙重雜湊後假陽性率極低,但仍做最終字串比較
if (s.substring(prevStart, prevStart + len) === s.substring(i, i + len)) {
return i;
}
}
seen.set(key, i);
}
return -1;
}
// 二元搜尋最長長度
let lo = 0, hi = n - 1;
let resultStart = -1, resultLen = 0;
while (lo <= hi) {
const mid = (lo + hi) >>> 1;
const idx = check(mid);
if (idx !== -1) {
resultStart = idx;
resultLen = mid;
lo = mid + 1; // 嘗試更長
} else {
hi = mid - 1; // 長度不夠,縮短
}
}
return resultStart === -1 ? "" : s.substring(resultStart, resultStart + resultLen);
}
// 測試
console.log(longestDupSubstring("banana")); // 輸出:"ana"(長度 3)
console.log(longestDupSubstring("abcd")); // 輸出:""(無重複)
複雜度:
- 時間:O(n log n)——二元搜尋 O(log n) 次,每次 Rolling Hash 驗證 O(n)
- 空間:O(n)——雜湊表儲存各子字串雜湊值
常見陷阱
1. Consistent Hashing 移除節點時忘記清除所有虛擬節點
// 錯誤:只移除一個虛擬節點,其他 149 個還在環上
function badRemove(ring: Map<number, string>, nodeId: string): void {
ring.delete(hash32(nodeId)); // 只刪一個!
}
// 正確:移除所有對應虛擬節點
function goodRemove(ring: ConsistentHashRing, nodeId: string): void {
ring.removeNode(nodeId); // 內部循環移除所有 virtualNodesPerServer 個
}
2. Cuckoo Hashing 忽略踢出循環的可能性
// 問題:若 h1(A)=h1(B)=0, h2(A)=h2(B)=0,A 踢 B,B 踢 A,無限循環
// 解法:設定最大踢出次數 CUCKOO_MAX_EVICTIONS,超過則 Rehash
// 另一個常見解法:Cuckoo Hashing 的負載因子應保持在 0.5 以下
3. Bloom Filter 沒有假陰性≠沒有任何錯誤
// Bloom Filter 的錯誤模式:
// ✓ 存在的元素 → 一定返回 true(無假陰性)
// ✗ 不存在的元素 → 可能返回 true(假陽性率可控)
// ✗ 不存在的元素 → 不可能返回 false(這才是 false negative,確實不存在)
// 正確使用方式:
// if (!filter.mightContain(url)) {
// // 確定不存在,可以安全跳過 DB 查詢
// } else {
// // 可能存在,需要查 DB 確認(因為可能是假陽性)
// const exists = await db.checkUrl(url);
// }
總結
進階雜湊技術的核心思想是:針對不同場景的限制,設計不同的取捨策略。
- Consistent Hashing:犧牲 O(1) 查找(改為 O(log N)),換取分散式節點增減時只影響 1/N 的 key,是 Memcached、Redis Cluster、Cassandra 等系統的核心基石
- Cuckoo Hashing:犧牲 O(1) 攤銷插入(需要踢出),換取 O(1) 最壞查找保證,適合快取查找場景
- Perfect Hashing:犧牲插入靈活性(靜態集合),換取零碰撞、O(1) 最壞查找,適合編譯器符號表
- Bloom Filter:犧牲精確性(允許假陽性),換取極低的記憶體占用,數十億元素只需幾 MB
這些技術在面試中常以「設計分散式快取」、「設計 URL 去重系統」、「設計推薦系統」等題目考察。
下一篇,我們將進入遞迴與回溯法(Recursion & Backtracking)——從遞迴樹的視覺化到剪枝優化,掌握 N-Queens、Sudoku Solver 等經典問題的系統化解題框架。
希望這篇文章能夠幫助你理解進階雜湊技術的核心原理與實際應用。如有任何問題或疑惑,歡迎到 Contact 頁面 留言交流!