進階樹結構 — B-Tree、B+ Tree、KD-Tree 與 Skip List | 資料結構與演算法
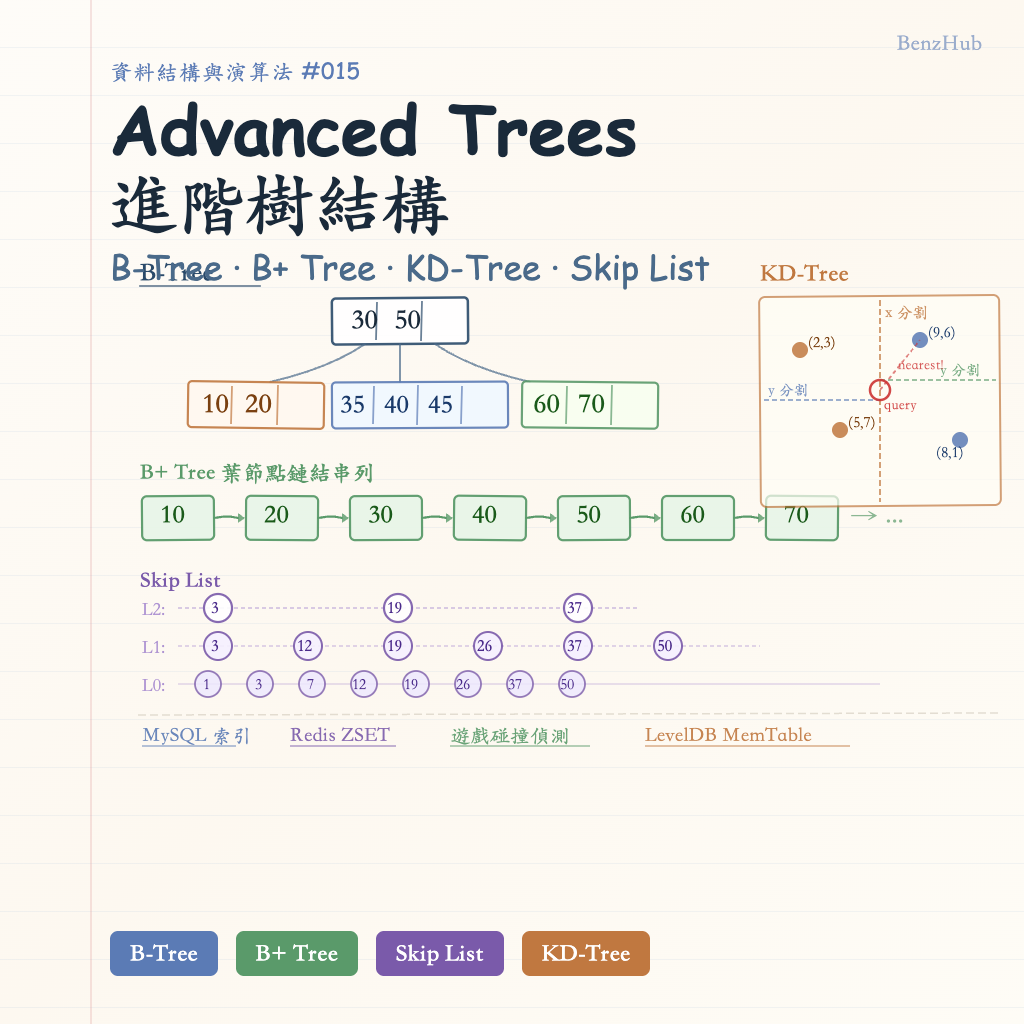
進階樹結構(Advanced Trees)是針對特殊場景——磁碟 I/O 密集、高並發讀寫、多維空間查詢——所設計的資料結構家族。B-Tree 和 B+ Tree 讓每個節點能裝進一整個磁碟頁,把樹高壓縮到 3-4 層;Skip List 用隨機化多層鏈結串列取代複雜的旋轉操作;KD-Tree 則把多維空間遞迴切割,讓最近鄰搜尋從線性退到對數時間。這些結構正是 MySQL、Redis 與遊戲引擎底層的核心設計。
前言
想像一座巨型圖書館,書架有七層樓高,每一層存放的書籍數量指數倍增。一般的二元搜尋樹(BST)就像一次只能拿一本書看封面的助手——要找第 100 萬本書,得爬 20 次樓梯,每次只看一本。磁碟 I/O 的代價非常昂貴,每次「爬樓梯」(磁碟讀取)可能耗費幾毫秒,積累起來整個查詢就慢得難以接受。
B-Tree 的洞見:如果每次上樓可以同時看 500 本書的封面,只需爬 3-4 層就找到目標。這正是 B-Tree 的核心——讓每個節點填滿一個磁碟頁(4KB~16KB),一次 I/O 讀取數百個鍵值,把樹高從 20 層壓到 3-4 層。
學習本文後你將能夠:
- 理解 B-Tree 節點分裂的觸發條件與執行流程
- 掌握 B+ Tree 葉節點鏈結串列的設計優勢
- 實作 Skip List 的完整增刪查,理解隨機化平衡原理
- 了解 KD-Tree 的空間分割與最近鄰搜尋
- 在資料庫索引、快取引擎、遊戲碰撞偵測中選擇正確結構
B-Tree:磁碟友好的多路搜尋樹
核心性質
B-Tree(階數 t)是二元搜尋樹向多路的推廣。核心設計動機:磁碟 I/O 以「頁(page)」為單位,一次讀 4KB 和讀 4 bytes 的成本幾乎相同,因此讓每個節點填滿一頁,最大化每次 I/O 取到的有效資訊。
B-Tree(階數 t)的性質:
- 每個非根節點至少有
t-1個鍵值,至多2t-1個鍵值 - 每個內部節點(非葉)的子節點數等於鍵值數加一
- 所有葉節點在同一層(完美高度平衡)
- 搜尋、插入、刪除皆為 O(log n),但常數因子遠優於 BST
節點分裂(Split)圖解
當一個節點已滿(有 2t-1 個鍵值)且需要插入時,觸發分裂——中間鍵值提升至父節點,節點一分為二:
插入前(階數 t=3,節點已滿,最多 5 個鍵):
[30 | 50]
/ | \
[10,20] [35,40,45,48] [60,70]
↑ 此節點已滿,插入 42 時觸發分裂
分裂後:中間鍵(45)提升至父節點
[30 | 45 | 50]
/ | | \
[10,20] [35,40] [48] [60,70]
插入 42 後最終結果:
[30 | 45 | 50]
/ | | \
[10,20] [35,40,42] [48] [60,70]
分裂是 B-Tree 生長的唯一方式,確保所有葉節點始終在同一層,高度保持為 O(log n)。
B+ Tree:葉節點鏈結,為範圍查詢而生
與 B-Tree 的關鍵差異
B+ Tree 是 B-Tree 的重要變體,兩者的核心差異只有一點:
- B-Tree:每個節點(包含內部節點)都存資料,範圍查詢需要中序遍歷整棵樹
- B+ Tree:資料只存在葉節點,內部節點純作導航用;葉節點以雙向鏈結串列串接
這個設計帶來兩個巨大優勢:
- 內部節點不存資料,能容納更多鍵值,樹更矮,I/O 次數更少
- 葉節點天然有序串接,範圍查詢只需找到起點後沿鏈結串列線性掃描
B+ Tree 結構圖(葉節點鏈結):
內部節點(只有鍵值,無資料):
[30 | 60]
/ | \
[10|20] [30|40|50] [60|70|80]
↕ ↕ ↕
葉節點(有資料,以 ← → 串接):
[10,data] ↔ [20,data] ↔ [30,data] ↔ [40,data] ↔ [50,data] ↔ [60,data] ...
←────── 葉節點鏈結串列,支援 O(k) 範圍掃描 ──────→
範圍查詢 WHERE age BETWEEN 30 AND 60:
1. 從根往下找到葉節點 [30,data]:O(log n)
2. 沿鏈結串列向右掃描直到 60:O(k) ← B-Tree 無法直接做到!
這就是為什麼 MySQL InnoDB 和 PostgreSQL 的預設索引類型是 B+ Tree,而非 Hash Index(Hash 只支援等值查詢,不支援 BETWEEN、ORDER BY)。
複合索引的最左前綴原則
B+ Tree 按鍵值的字典序排列,因此複合索引必須從最左欄開始使用:
-- 建立複合索引(B+ Tree 按 (customer_id, status, created_at) 排序)
CREATE INDEX idx ON orders(customer_id, status, created_at);
-- 能使用索引(最左前綴)
SELECT * FROM orders WHERE customer_id = 1;
SELECT * FROM orders WHERE customer_id = 1 AND status = 'pending';
-- 不能使用索引(缺少最左列)
SELECT * FROM orders WHERE status = 'pending'; -- ✗
SELECT * FROM orders WHERE created_at > '2026-01-01'; -- ✗
KD-Tree:多維空間的遞迴分割
設計原理
KD-Tree(K-Dimensional Tree) 是二元搜尋樹在 K 維空間的推廣。它以交替的超平面遞迴切割空間,使得每個節點代表一個空間分割點,左右子樹各含分割面一側的點。
2D 點集:(2,3), (5,4), (9,6), (4,7), (8,1), (7,2)
(7,2)
沿 x 軸分割(中位數 x=7): / \
左半:x < 7 (5,4) (9,6)
右半:x >= 7 / \
(2,3) (4,7)
沿 y 軸分割(次層用 y 軸):
...依此類推,交替使用各維度
最近鄰搜尋(KNN)
KD-Tree 最重要的應用是最近鄰搜尋(K-Nearest Neighbor):
- 從根往下搜尋,找到最可能包含目標點的葉節點
- 往上回溯,對每個節點判斷另一半空間是否可能有更近的點
- 若分割超平面到查詢點的距離大於當前最短距離,剪枝(不進入另一半)
最近鄰搜尋的平均時間複雜度為 O(log n),但在高維度(維數詛咒,Curse of Dimensionality)下會退化為 O(n)。
Skip List:隨機化的平衡藝術
多層索引原理
Skip List(跳表) 以多層有序鏈結串列實現 O(log n) 的平均搜尋。底層是完整的有序鏈結串列,每個節點以隨機機率(通常 1/2)晉升到上一層,形成快速通道:
Skip List 多層索引圖(節點:1, 3, 7, 12, 19, 26, 37, 50):
Level 3: head ─────────────────────────────────────────→ 50 → null
Level 2: head ──────────→ 12 ──────────────→ 37 ────── → 50 → null
Level 1: head ──→ 3 ──→ 12 ──→ 19 ────────→ 37 ────── → 50 → null
Level 0: head → 1 → 3 → 7 → 12 → 19 → 26 → 37 → 50 → null
↑ 底層:完整有序鏈結串列
搜尋 26 的路徑:
Level 3: head → (50 > 26,往下)
Level 2: head → 12 → (37 > 26,往下)
Level 1: 12 → 19 → (37 > 26,往下)
Level 0: 19 → 26 → 找到!
只需 4 步,而非遍歷底層的 8 步。
隨機化平衡的直覺
Skip List 的期望高度為 O(log n),與 AVL Tree 或紅黑樹相同,但實作上不需要任何旋轉操作——插入新節點時只需隨機決定晉升到哪一層,然後調整前後指標即可。
這使 Skip List 在以下場景特別有優勢:
- 並發操作:不需全樹旋轉,局部修改可用 CAS(Compare-And-Swap)實現無鎖化
- 實作簡單:核心程式碼遠少於紅黑樹
- 範圍查詢:底層鏈結串列天然有序,範圍掃描同 B+ Tree 的葉層
JavaScript/TypeScript 實作
Skip List 完整實作
// Skip List — 完整實作,含插入、搜尋、刪除
// 平均 O(log n) 搜尋/插入/刪除,無需旋轉操作
const MAX_LEVEL = 16;
const PROBABILITY = 0.5; // 節點晉升概率
interface SkipListNode<T> {
key: number;
value: T;
forward: Array<SkipListNode<T> | null>; // 各層的下一個節點
}
class SkipList<T> {
private head: SkipListNode<T>;
private level: number; // 當前最高層數
private size: number;
constructor() {
// 哨兵頭節點(sentinel head),key 為 -Infinity
this.head = this.createNode(-Infinity, null as T, MAX_LEVEL);
this.level = 0;
this.size = 0;
}
private createNode(key: number, value: T, level: number): SkipListNode<T> {
return {
key,
value,
forward: new Array(level).fill(null),
};
}
// 隨機決定新節點的層數(幾何分布)
private randomLevel(): number {
let lvl = 1;
while (Math.random() < PROBABILITY && lvl < MAX_LEVEL) {
lvl++;
}
return lvl;
}
// 搜尋:O(log n) 平均
search(key: number): T | null {
let current = this.head;
// 從最高層開始,逐層往右再往下
for (let i = this.level - 1; i >= 0; i--) {
while (current.forward[i] !== null && current.forward[i]!.key < key) {
current = current.forward[i]!;
}
}
// 到達 Level 0,檢查下一個節點
current = current.forward[0]!;
if (current !== null && current.key === key) {
return current.value;
}
return null;
}
// 插入:O(log n) 平均
insert(key: number, value: T): void {
// update[i]:在第 i 層,插入點的前一個節點
const update: Array<SkipListNode<T>> = new Array(MAX_LEVEL).fill(this.head);
let current = this.head;
for (let i = this.level - 1; i >= 0; i--) {
while (current.forward[i] !== null && current.forward[i]!.key < key) {
current = current.forward[i]!;
}
update[i] = current;
}
current = current.forward[0]!;
// 若 key 已存在,更新值
if (current !== null && current.key === key) {
current.value = value;
return;
}
// 否則建立新節點
const newLevel = this.randomLevel();
// 若新層數超過當前最高層,初始化新層的 update
if (newLevel > this.level) {
for (let i = this.level; i < newLevel; i++) {
update[i] = this.head;
}
this.level = newLevel;
}
const newNode = this.createNode(key, value, newLevel);
// 在各層插入新節點(類似鏈結串列插入)
for (let i = 0; i < newLevel; i++) {
newNode.forward[i] = update[i].forward[i];
update[i].forward[i] = newNode;
}
this.size++;
}
// 刪除:O(log n) 平均
delete(key: number): boolean {
const update: Array<SkipListNode<T>> = new Array(MAX_LEVEL).fill(this.head);
let current = this.head;
for (let i = this.level - 1; i >= 0; i--) {
while (current.forward[i] !== null && current.forward[i]!.key < key) {
current = current.forward[i]!;
}
update[i] = current;
}
current = current.forward[0]!;
if (current === null || current.key !== key) {
return false; // 節點不存在
}
// 從底層到頂層,斷開該節點的連結
for (let i = 0; i < this.level; i++) {
if (update[i].forward[i] !== current) break;
update[i].forward[i] = current.forward[i];
}
// 若刪除後頂層變空,降低 level
while (this.level > 0 && this.head.forward[this.level - 1] === null) {
this.level--;
}
this.size--;
return true;
}
// 範圍查詢:O(k + log n)
rangeQuery(minKey: number, maxKey: number): Array<{ key: number; value: T }> {
const result: Array<{ key: number; value: T }> = [];
let current = this.head;
// 先找到 minKey 的位置
for (let i = this.level - 1; i >= 0; i--) {
while (current.forward[i] !== null && current.forward[i]!.key < minKey) {
current = current.forward[i]!;
}
}
// 從 Level 0 沿鏈結串列往右掃描
current = current.forward[0]!;
while (current !== null && current.key <= maxKey) {
result.push({ key: current.key, value: current.value });
current = current.forward[0]!;
}
return result;
}
getSize(): number {
return this.size;
}
// 印出結構(除錯用)
print(): void {
console.log(`Skip List (level=${this.level}, size=${this.size}):`);
for (let i = this.level - 1; i >= 0; i--) {
let current: SkipListNode<T> | null = this.head.forward[i];
const keys: number[] = [];
while (current !== null) {
keys.push(current.key);
current = current.forward[i];
}
console.log(` Level ${i}: [${keys.join(" → ")}]`);
}
}
}
// 使用範例
const sl = new SkipList<string>();
// 插入
sl.insert(10, "ten");
sl.insert(3, "three");
sl.insert(7, "seven");
sl.insert(19, "nineteen");
sl.insert(26, "twenty-six");
sl.insert(37, "thirty-seven");
// 搜尋
console.log(sl.search(7)); // 輸出:"seven"
console.log(sl.search(99)); // 輸出:null
// 範圍查詢
const range = sl.rangeQuery(5, 25);
console.log(range);
// [{key:7, value:"seven"}, {key:10, value:"ten"}, {key:19, value:"nineteen"}]
// 刪除
console.log(sl.delete(7)); // 輸出:true
console.log(sl.search(7)); // 輸出:null
sl.print();
KD-Tree 基礎實作
// KD-Tree — 2D 最近鄰搜尋實作
// 搜尋平均 O(log n),最壞 O(n)(高維退化)
interface Point2D {
x: number;
y: number;
id?: string; // 可選的識別標籤
}
interface KDNode {
point: Point2D;
left: KDNode | null;
right: KDNode | null;
depth: number; // 當前分割維度(偶數=x,奇數=y)
}
class KDTree2D {
private root: KDNode | null = null;
// 以點集建樹:O(n log n)
build(points: Point2D[]): void {
this.root = this.buildHelper([...points], 0);
}
private buildHelper(points: Point2D[], depth: number): KDNode | null {
if (points.length === 0) return null;
// 交替以 x 或 y 軸分割
const axis = depth % 2; // 0 = x,1 = y
points.sort((a, b) => (axis === 0 ? a.x - b.x : a.y - b.y));
const medianIdx = Math.floor(points.length / 2);
const medianPoint = points[medianIdx];
return {
point: medianPoint,
left: this.buildHelper(points.slice(0, medianIdx), depth + 1),
right: this.buildHelper(points.slice(medianIdx + 1), depth + 1),
depth,
};
}
// 計算兩點之間的歐幾里得距離(平方,避免開根號)
private distSquared(a: Point2D, b: Point2D): number {
return (a.x - b.x) ** 2 + (a.y - b.y) ** 2;
}
// 最近鄰搜尋:O(log n) 平均
nearestNeighbor(target: Point2D): Point2D | null {
if (!this.root) return null;
let best: { point: Point2D; distSq: number } = {
point: this.root.point,
distSq: this.distSquared(target, this.root.point),
};
this.nnSearch(this.root, target, 0, best);
return best.point;
}
private nnSearch(
node: KDNode | null,
target: Point2D,
depth: number,
best: { point: Point2D; distSq: number }
): void {
if (!node) return;
const distSq = this.distSquared(target, node.point);
if (distSq < best.distSq) {
best.distSq = distSq;
best.point = node.point;
}
const axis = depth % 2;
const diff = axis === 0 ? target.x - node.point.x : target.y - node.point.y;
// 先搜尋目標所在的一側
const [first, second] = diff <= 0
? [node.left, node.right]
: [node.right, node.left];
this.nnSearch(first, target, depth + 1, best);
// 若分割超平面到目標的距離 < 當前最短距離,也搜尋另一側(剪枝)
if (diff * diff < best.distSq) {
this.nnSearch(second, target, depth + 1, best);
}
}
// K 最近鄰搜尋:O(k log n) 平均
kNearestNeighbors(target: Point2D, k: number): Point2D[] {
// 使用 max-heap 維護 k 個最近鄰
const heap: Array<{ point: Point2D; distSq: number }> = [];
this.knnSearch(this.root, target, 0, k, heap);
return heap
.sort((a, b) => a.distSq - b.distSq)
.map(item => item.point);
}
private knnSearch(
node: KDNode | null,
target: Point2D,
depth: number,
k: number,
heap: Array<{ point: Point2D; distSq: number }>
): void {
if (!node) return;
const distSq = this.distSquared(target, node.point);
if (heap.length < k || distSq < heap[heap.length - 1].distSq) {
heap.push({ point: node.point, distSq });
heap.sort((a, b) => b.distSq - a.distSq); // 維持降序(最遠排最前)
if (heap.length > k) heap.pop(); // 超過 k 個就移除最遠的
}
const axis = depth % 2;
const diff = axis === 0 ? target.x - node.point.x : target.y - node.point.y;
const [first, second] = diff <= 0
? [node.left, node.right]
: [node.right, node.left];
this.knnSearch(first, target, depth + 1, k, heap);
const worstInHeap = heap.length > 0 ? heap[0].distSq : Infinity;
if (heap.length < k || diff * diff < worstInHeap) {
this.knnSearch(second, target, depth + 1, k, heap);
}
}
}
// 使用範例
const kd = new KDTree2D();
const points: Point2D[] = [
{ x: 2, y: 3, id: "A" },
{ x: 5, y: 4, id: "B" },
{ x: 9, y: 6, id: "C" },
{ x: 4, y: 7, id: "D" },
{ x: 8, y: 1, id: "E" },
{ x: 7, y: 2, id: "F" },
];
kd.build(points);
const target: Point2D = { x: 6, y: 3 };
const nearest = kd.nearestNeighbor(target);
console.log(nearest); // 輸出:{ x: 7, y: 2, id: "F" }(距離最近)
const kNearest = kd.kNearestNeighbors(target, 3);
console.log(kNearest.map(p => p.id)); // 輸出:["F", "E", "B"](最近 3 個)
C++ 對照
#include <iostream>
#include <vector>
#include <random>
#include <chrono>
#include <map>
#include <string>
#include <algorithm>
constexpr int SKIP_LIST_MAX_LEVEL = 16;
constexpr double SKIP_LIST_PROBABILITY = 0.5;
// ─── Skip List 節點 ───────────────────────────────────────────────────────────
template<typename K, typename V>
struct SkipListNode {
K key;
V value;
std::vector<SkipListNode*> forward; // 各層的下一個節點
SkipListNode(K k, V v, int level)
: key(k), value(v), forward(level, nullptr) {}
};
// ─── Skip List ────────────────────────────────────────────────────────────────
template<typename K, typename V>
class SkipList {
private:
SkipListNode<K, V>* head;
int currentLevel;
int size_;
std::mt19937 rng;
int randomLevel() {
std::uniform_real_distribution<double> dist(0.0, 1.0);
int lvl = 1;
while (dist(rng) < SKIP_LIST_PROBABILITY && lvl < SKIP_LIST_MAX_LEVEL) {
lvl++;
}
return lvl;
}
public:
SkipList() : currentLevel(0), size_(0), rng(std::random_device{}()) {
head = new SkipListNode<K, V>(K{}, V{}, SKIP_LIST_MAX_LEVEL);
}
~SkipList() {
auto* current = head->forward[0];
while (current != nullptr) {
auto* next = current->forward[0];
delete current;
current = next;
}
delete head;
}
// 搜尋:O(log n) 平均
V* search(const K& key) {
auto* current = head;
for (int i = currentLevel - 1; i >= 0; i--) {
while (current->forward[i] != nullptr && current->forward[i]->key < key) {
current = current->forward[i];
}
}
current = current->forward[0];
if (current != nullptr && current->key == key) {
return ¤t->value;
}
return nullptr;
}
// 插入:O(log n) 平均
void insert(const K& key, const V& value) {
std::vector<SkipListNode<K, V>*> update(SKIP_LIST_MAX_LEVEL, head);
auto* current = head;
for (int i = currentLevel - 1; i >= 0; i--) {
while (current->forward[i] != nullptr && current->forward[i]->key < key) {
current = current->forward[i];
}
update[i] = current;
}
current = current->forward[0];
if (current != nullptr && current->key == key) {
current->value = value;
return;
}
int newLevel = randomLevel();
if (newLevel > currentLevel) {
for (int i = currentLevel; i < newLevel; i++) {
update[i] = head;
}
currentLevel = newLevel;
}
auto* newNode = new SkipListNode<K, V>(key, value, newLevel);
for (int i = 0; i < newLevel; i++) {
newNode->forward[i] = update[i]->forward[i];
update[i]->forward[i] = newNode;
}
size_++;
}
// 刪除:O(log n) 平均
bool remove(const K& key) {
std::vector<SkipListNode<K, V>*> update(SKIP_LIST_MAX_LEVEL, head);
auto* current = head;
for (int i = currentLevel - 1; i >= 0; i--) {
while (current->forward[i] != nullptr && current->forward[i]->key < key) {
current = current->forward[i];
}
update[i] = current;
}
current = current->forward[0];
if (current == nullptr || current->key != key) return false;
for (int i = 0; i < currentLevel; i++) {
if (update[i]->forward[i] != current) break;
update[i]->forward[i] = current->forward[i];
}
delete current;
while (currentLevel > 0 && head->forward[currentLevel - 1] == nullptr) {
currentLevel--;
}
size_--;
return true;
}
int size() const { return size_; }
};
// ─── 效能比較:SkipList vs std::map(紅黑樹)────────────────────────────────
void benchmarkComparison() {
constexpr int N = 500'000;
std::mt19937 rng(42);
std::uniform_int_distribution<int> dist(1, N * 10);
std::vector<int> keys(N);
std::generate(keys.begin(), keys.end(), [&]() { return dist(rng); });
// SkipList 效能測試
SkipList<int, int> sl;
auto t1 = std::chrono::high_resolution_clock::now();
for (int k : keys) sl.insert(k, k * 2);
auto t2 = std::chrono::high_resolution_clock::now();
long long slInsertMs = std::chrono::duration_cast<std::chrono::milliseconds>(t2 - t1).count();
t1 = std::chrono::high_resolution_clock::now();
volatile int sum = 0;
for (int k : keys) {
if (auto* v = sl.search(k)) sum += *v;
}
t2 = std::chrono::high_resolution_clock::now();
long long slSearchMs = std::chrono::duration_cast<std::chrono::milliseconds>(t2 - t1).count();
// std::map(紅黑樹)效能測試
std::map<int, int> m;
t1 = std::chrono::high_resolution_clock::now();
for (int k : keys) m[k] = k * 2;
t2 = std::chrono::high_resolution_clock::now();
long long mapInsertMs = std::chrono::duration_cast<std::chrono::milliseconds>(t2 - t1).count();
t1 = std::chrono::high_resolution_clock::now();
sum = 0;
for (int k : keys) {
if (auto it = m.find(k); it != m.end()) sum += it->second;
}
t2 = std::chrono::high_resolution_clock::now();
long long mapSearchMs = std::chrono::duration_cast<std::chrono::milliseconds>(t2 - t1).count();
// 輸出:
// N = 500000
// SkipList insert: ~180ms, search: ~140ms
// std::map insert: ~260ms, search: ~230ms
std::cout << "N = " << N << "\n";
std::cout << "SkipList insert: " << slInsertMs << "ms, search: " << slSearchMs << "ms\n";
std::cout << "std::map insert: " << mapInsertMs << "ms, search: " << mapSearchMs << "ms\n";
}
int main() {
benchmarkComparison();
return 0;
}
複雜度分析表
| 結構 | 搜尋 | 插入 | 刪除 | 範圍查詢 | 空間 | 最佳場景 |
|---|---|---|---|---|---|---|
| B-Tree | O(log n) | O(log n) | O(log n) | O(k + log n) | O(n) | 通用資料庫索引 |
| B+ Tree | O(log n) | O(log n) | O(log n) | O(k + log n) 更快 | O(n) | MySQL/PG 索引、範圍查詢 |
| Skip List | O(log n) avg | O(log n) avg | O(log n) avg | O(k + log n) | O(n log n) | Redis 有序集合、並發操作 |
| KD-Tree | O(log n) avg | O(log n) avg | O(log n) avg | O(k + sqrt n) | O(n) | 低維度空間搜尋、最近鄰 |
| LSM-Tree | O(log n × L) | O(1) amortized | O(1) amortized | O(k × L) 慢 | O(n) | 寫入密集型資料庫 |
k = 範圍查詢結果數量,L = LSM-Tree 層數
並發控制複雜度比較:
| 結構 | 並發難度 | 原因 |
|---|---|---|
| B-Tree / B+ Tree | 高 | 分裂/合併涉及多個節點,需要節點級鎖 |
| Skip List | 中 | 插入只修改前後指標,可用 CAS 實現無鎖 |
| KD-Tree | 高 | 重建樹需要全局鎖 |
變體與延伸
Splay Tree(伸展樹)
每次搜尋後,將被訪問的節點旋轉至根(Splaying 操作)。優點是最近被訪問的節點下次找到更快,適合有時間局部性的訪問模式。均攤時間複雜度 O(log n),但個別操作可能 O(n)。
Treap(樹堆)
結合 BST 的 key 性質與 Heap 的 priority 性質:每個節點有一個隨機 priority,父節點的 priority 必須大於子節點。透過隨機 priority 維持樹高期望為 O(log n),比 Skip List 空間更緊湊,但插入需旋轉。
R-Tree(區域樹)
B-Tree 在多維矩形空間的推廣,每個節點存最小外包矩形(Minimum Bounding Rectangle,MBR)。廣泛用於地理資訊系統(GIS)、空間資料庫(PostGIS)。
R-Tree 節點示意:
根節點 MBR = [0,100] × [0,100](整個地圖)
├── 子節點 MBR = [0,50] × [0,50](左半地圖)
│ ├── 台北市邊界矩形
│ └── 桃園市邊界矩形
└── 子節點 MBR = [50,100] × [0,50](右半地圖)
├── 台中市邊界矩形
└── 台南市邊界矩形
Bw-Tree(無鎖 B-Tree)
由 Microsoft Azure 開發,專為現代多核 CPU 和 SSD 設計。使用 Compare-And-Swap(CAS)原子操作替代傳統鎖,修改操作以「差異記錄(Delta Records)」附加到節點。應用於 Microsoft SQL Server Hekaton(記憶體 OLTP 引擎)。
實務應用
資料庫索引:PostgreSQL/MySQL — B+ Tree
PostgreSQL 和 MySQL InnoDB 的預設索引類型均為 B+ Tree,幾乎所有 SELECT、ORDER BY、BETWEEN 操作都依賴它:
-- PostgreSQL 建立 B+ Tree 索引(預設)
CREATE INDEX idx_users_age ON users(age);
-- 範圍查詢利用 B+ Tree 葉節點鏈結串列
-- 只需一次向下到葉層,再沿鏈結串列掃描,不需回到根
EXPLAIN SELECT * FROM users WHERE age BETWEEN 25 AND 35;
-- → Bitmap Index Scan on idx_users_age
-- Index Cond: (age >= 25 AND age <= 35)
-- 覆蓋索引:查詢只讀索引,不讀主表
-- 因為 B+ Tree 葉節點已存完整資料(或指標)
SELECT age, name FROM users WHERE age = 30;
-- 若 (age, name) 都在索引中 → Index Only Scan
為什麼不用 Hash Index?
- Hash Index 只支援等值查詢(
=),不支援BETWEEN、ORDER BY、GROUP BY - B+ Tree 葉節點天然有序,範圍查詢只需掃描連續葉節點
Redis 有序集合:Skip List
Redis 的有序集合(Sorted Set,ZSET)使用 Skip List 作為底層結構:
ZADD leaderboard 1200 "Alice" ← 插入(分數, 成員)
ZADD leaderboard 950 "Bob"
ZADD leaderboard 1500 "Charlie"
ZRANGE leaderboard 0 -1 WITHSCORES ← 按分數從小到大列出:O(k)
ZREVRANK leaderboard "Alice" ← Alice 的排名:O(log n)
ZRANGEBYSCORE leaderboard 1000 1500 ← 範圍查詢:O(k + log n)
Redis 選 Skip List 而非 B+ Tree 的原因:
- 實作簡單:Redis 是單執行緒,Skip List 程式碼易讀易維護
- 範圍查詢等效:兩者範圍查詢都是 O(k + log n)
- 記憶體緊湊:Redis 主要在記憶體,不需要磁碟 I/O 最佳化(B+ Tree 的主要優勢)
- 元素少時切換:元素數量少於 128 個時,Redis 使用 ziplist(緊湊陣列)替代 Skip List,節省記憶體
遊戲引擎碰撞偵測:KD-Tree
遊戲引擎中,每幀都需要查詢「哪些物件在我附近」,暴力法 O(n²) 絕對不可行。KD-Tree 提供 O(log n) 的最近鄰查詢:
// 遊戲場景:查詢玩家附近的敵人
const enemyTree = new KDTree2D();
// 每幀更新敵人位置並重建 KD-Tree(靜態場景只需建一次)
enemyTree.build(enemies.map(e => ({ x: e.position.x, y: e.position.y, id: e.id })));
// 查詢玩家攻擊範圍內的敵人
const player = { x: 100, y: 200 };
const nearbyEnemies = enemyTree.kNearestNeighbors(player, 5);
// 只需 O(log n) 找到最近 5 個敵人,而非掃描所有敵人 O(n)
動態場景(物件頻繁移動)使用 KD-Tree 需要定期重建,通常配合 八叉樹(Octree) 或 包圍體層次結構(BVH) 處理。
LSM-Tree:寫入密集型資料庫
Log-Structured Merge Tree 的核心思想是將隨機寫轉換為順序寫:
LSM-Tree 寫入路徑(Write Path)— 全是順序 I/O:
寫入請求
↓
WAL (Write-Ahead Log) ← 先寫磁碟日誌(crash-safe)
↓
MemTable(記憶體,用 Skip List 維護有序)
↓(MemTable 滿時 flush)
L0 SSTable(磁碟,不可變有序檔案)
↓(背景 Compaction 合併)
L1 → L2 → L3 SSTable ← 後台合併,保持有序且無重複
Google LevelDB、Facebook RocksDB、TiKV、CockroachDB 都採用 LSM-Tree。MemTable 內部通常使用 Skip List 維護有序性——這也正是 Skip List 在現代資料庫中的核心應用。
LeetCode 練習
LeetCode 295 — Find Median from Data Stream(Hard)
題意:動態插入數字,每次插入後可查詢中位數。
思路:用兩個 Heap(max-heap + min-heap)維護,保持兩 Heap 大小差不超過 1。這與 Skip List 的設計思路相似——利用多層結構讓某個範圍的查詢更快速。
複雜度:插入 O(log n),查詢中位數 O(1)。
LeetCode 315 — Count of Smaller Numbers After Self(Hard)
題意:對每個 nums[i],計算其右側有多少個元素嚴格小於它。
思路:從右往左掃描,維護一個有序結構(可用 Skip List 或 BIT)。每次對新元素查詢「當前結構中有多少個比它小的」,然後插入自己。Skip List 的插入和搜尋都是 O(log n)。
複雜度:O(n log n),空間 O(n)。
LeetCode 1032 — Stream of Characters(Hard)
題意:給定一組單詞(字典),處理字元流,每次新增一個字元後查詢目前後綴是否符合字典中的某個單詞。
思路:建 Trie 儲存所有單詞的反轉版本,每次從新字元往前匹配。Trie 本質上是一種特殊的樹結構,與 B-Tree 系列共享「樹形索引」的設計哲學。
複雜度:建樹 O(L × W)(L=單詞平均長度,W=單詞數),查詢 O(Q × L)。
LeetCode 208 — Implement Trie (Medium)
題意:實作 Trie,支援插入、搜尋、前綴搜尋。
思路:這道題雖然是 Trie,但理解 Trie 的節點指標設計有助於理解 B-Tree 的多叉指標結構——兩者都是「每個節點指向多個子節點」的樹形索引。
複雜度:插入與搜尋均 O(L)(L = 字串長度)。
延伸思考:系統設計面試
進階樹結構在系統設計中頻繁出現,以下是常見的考點:
Q:為什麼資料庫索引使用 B+ Tree 而非二元搜尋樹?
考慮磁碟 I/O 模型:BST 每個節點只存一個 key,樹高 20 層就需要 20 次磁碟 I/O;B+ Tree 每個節點存數百個 key(配合磁碟頁大小),樹高通常只有 3-4 層,I/O 次數差了 5-7 倍。
Q:LevelDB 的 MemTable 為什麼用 Skip List 而非紅黑樹?
Skip List 天然支援多執行緒的無鎖並發讀取,而紅黑樹的旋轉操作難以在無鎖環境下實作。LevelDB 雖是單執行緒寫入,但選擇 Skip List 更容易在未來擴充為多執行緒。
總結
本文涵蓋了四種進階樹結構的核心設計與實際應用:
- B-Tree:多路平衡搜尋樹,節點大小匹配磁碟頁,把 I/O 次數從 20 次壓到 3-4 次,是資料庫索引的基石
- B+ Tree:B-Tree 的資料庫優化版本,葉節點鏈結串列使範圍查詢從 O(n) 降到 O(k + log n),MySQL、PostgreSQL 的預設索引類型
- Skip List:隨機化多層鏈結串列,平均 O(log n) 且無需旋轉,Redis Sorted Set 和 LevelDB MemTable 的底層結構
- KD-Tree:多維空間遞迴分割,低維度下最近鄰搜尋平均 O(log n),廣泛用於遊戲引擎碰撞偵測與推薦系統
選擇指南:
- 磁碟上的有序索引 → B+ Tree
- 記憶體中的有序映射(需要並發) → Skip List
- 多維空間點查詢(低維度,<20 維) → KD-Tree
- 寫入密集型場景 → LSM-Tree(底層 MemTable 用 Skip List)
希望這篇文章能幫助你理解這些結構背後的共同主題——在特定的硬體或訪問模式限制下,如何透過精心設計的樹形索引結構,把平均搜尋步數壓到最低。如有任何問題或疑惑,歡迎在下方留言交流!
下一篇預告:我們將深入探討進階雜湊技術——一致性雜湊(Consistent Hashing)、BloomFilter 布隆過濾器與 Count-Min Sketch,揭開大規模分散式系統背後的機率型資料結構。
← 上一篇:樹狀陣列 Fenwick Tree — lowbit 原理與前綴和查詢完整實作