併查集 Union-Find — 路徑壓縮與按秩合併完整教學 | 資料結構與演算法
併查集(Union-Find) 是處理動態連通性(Dynamic Connectivity)問題的神器。它以近乎 O(1) 的攤銷時間,判斷任意兩個元素是否屬於同一集合、將兩個集合合併。透過路徑壓縮與按秩合併兩大優化,Union-Find 成為 Kruskal 最小生成樹、社群網路好友圈等問題的核心工具。
前言
想像你是 Facebook 的工程師,需要即時回答一個問題:「A 和 B 是否在同一個好友圈?」
每天有數百萬筆新的好友關係加入,如果每次查詢都用 BFS 或 DFS 遍歷圖,O(V+E) 的時間根本跟不上。有沒有辦法在大量動態更新的情況下,依然以近乎常數時間回答連通性問題?
答案是併查集(Union-Find,又稱 Disjoint Set Union,DSU)。
本文學習要點:
- 不相交集合森林的概念與直覺理解
- Find 操作:路徑壓縮的兩種實作(迭代 vs 遞迴)
- Union 操作:按秩合併防止樹退化
- TypeScript 完整實作(含加權併查集)
- C++ 對照實作(陣列版 + 模板版)
- 逆 Ackermann 函數 α(n) 的意義
- 帶權、可撤銷、持久化等變體
- 五道 LeetCode 精選題目解析
核心概念
不相交集合(Disjoint Set)
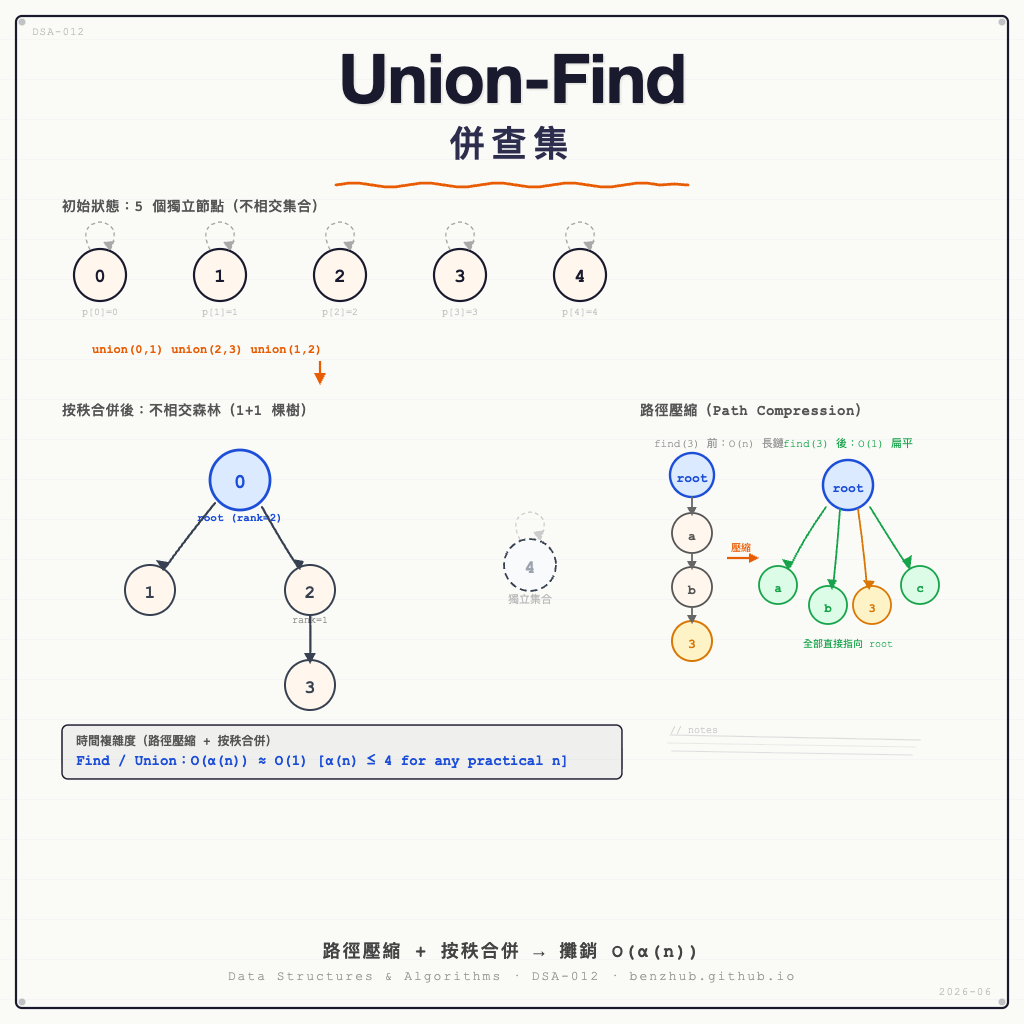
不相交集合(Disjoint Set) 是一組互不重疊的集合,每個元素只屬於其中一個集合。初始時,n 個元素各自形成一個單元素集合。
併查集用有根樹表示每個集合:樹的根節點是集合的代表元素(Representative),每個節點只記錄自己的父節點(parent[i])。初始狀態下每個節點都是自己的根:
初始:5 個元素,5 個獨立集合
0 1 2 3 4
↑ ↑ ↑ ↑ ↑
(0) (1) (2) (3) (4)
parent = [0, 1, 2, 3, 4] ← parent[i] = i,自己是自己的根
rank = [0, 0, 0, 0, 0]
Find 操作:找代表元素
Find(x) 沿父指針向上走,直到找到根(parent[x] == x),返回根作為集合代表。兩元素 Find 結果相同 → 屬於同一集合。
未優化時,退化的長鏈(類似 Linked List)使 Find 需要 O(n) 步。路徑壓縮(Path Compression) 在 Find 時把路徑上所有節點的 parent 直接改為根,大幅壓縮後續查詢路徑:
Find(3) 前的退化長鏈: Find(3) 後(路徑壓縮):
root root
| / | \ \
a →→→ a b c 3
|
b ← 路徑上所有節點直接指向 root
|
c
|
3
Union 操作:合併兩集合
Union(x, y) 找到 x 和 y 各自的根,若不同則將一棵樹的根指向另一棵樹的根。
未優化時,每次 Union 可能把高樹掛在低樹下,形成越來越高的長鏈。按秩合併(Union by Rank) 始終將秩(rank,近似樹高)較小的樹掛在較大樹下,防止退化:
Union(0,1):rank 相等 → 1 掛在 0 下,rank[0] 升為 1
0
|
1
Union(2,3):rank 相等 → 3 掛在 2 下,rank[2] 升為 1
0 2
| |
1 3
Union(1,2) → Union(Find(1), Find(2)) = Union(0, 2)
rank[0]=1, rank[2]=1,相等 → 2 掛在 0 下,rank[0] 升為 2
0
/ \
1 2
|
3
parent = [0, 0, 0, 2, 4]
rank = [2, 0, 1, 0, 0]
JavaScript / TypeScript 實作
標準 UnionFind 類別
class UnionFind {
private parent: number[];
private rank: number[];
private _count: number; // 當前不相交集合(連通分量)的數量
constructor(n: number) {
this.parent = Array.from({ length: n }, (_, i) => i); // parent[i] = i
this.rank = new Array(n).fill(0);
this._count = n; // 初始時每個節點各是一個集合
}
// Find with 路徑壓縮(迭代版,避免遞迴棧溢出)
find(x: number): number {
let root = x;
// 第一步:找到根節點
while (this.parent[root] !== root) {
root = this.parent[root];
}
// 第二步:路徑壓縮——將路徑上所有節點直接指向根
while (this.parent[x] !== root) {
const next = this.parent[x];
this.parent[x] = root;
x = next;
}
return root;
}
// 遞迴版路徑壓縮(程式碼更簡潔,小資料集適用)
findRecursive(x: number): number {
if (this.parent[x] !== x) {
this.parent[x] = this.findRecursive(this.parent[x]); // 尾遞迴壓縮
}
return this.parent[x];
}
// Union by Rank,返回是否成功合併(false = 已在同一集合)
union(x: number, y: number): boolean {
const rootX = this.find(x);
const rootY = this.find(y);
if (rootX === rootY) return false; // 已連通,不需合併
// 將秩較小的樹掛在秩較大的樹下
if (this.rank[rootX] < this.rank[rootY]) {
this.parent[rootX] = rootY;
} else if (this.rank[rootX] > this.rank[rootY]) {
this.parent[rootY] = rootX;
} else {
// 秩相同:任選一方向,並將根的秩 +1
this.parent[rootY] = rootX;
this.rank[rootX]++;
}
this._count--; // 合併後連通分量數減一
return true;
}
// 判斷兩元素是否連通
connected(x: number, y: number): boolean {
return this.find(x) === this.find(y);
}
// 當前不相交集合(連通分量)的數量
get count(): number {
return this._count;
}
}
// 使用範例
const uf = new UnionFind(6);
uf.union(0, 1);
uf.union(1, 2);
uf.union(3, 4);
console.log(uf.connected(0, 2)); // 輸出:true
console.log(uf.connected(0, 3)); // 輸出:false
console.log(uf.count); // 輸出:3(集合 {0,1,2}、{3,4}、{5})
加權併查集(Weighted Union-Find)
加權併查集在每條父邊附帶數值(比值或差值),Find 時沿路徑累積計算。典型應用是 LeetCode 399(評估除法):
// 帶權併查集:每條邊記錄 x 相對於 parent[x] 的倍數關係
// 常見應用:LeetCode 399(Evaluate Division)
class WeightedUnionFind {
private parent: number[];
private weight: number[]; // weight[x] = x 相對於 parent[x] 的倍數
constructor(n: number) {
this.parent = Array.from({ length: n }, (_, i) => i);
this.weight = new Array(n).fill(1.0); // 初始時 weight[i]=1(相對自身)
}
// 返回 [root, x 相對於 root 的倍數]
find(x: number): [number, number] {
if (this.parent[x] === x) return [x, 1.0];
const [root, parentWeight] = this.find(this.parent[x]);
// 路徑壓縮:直接將 x 指向 root,更新累積倍數
this.parent[x] = root;
this.weight[x] *= parentWeight; // x 相對 root = x 相對 parent × parent 相對 root
return [root, this.weight[x]];
}
// 合併:x / y = value(即 x = value × y)
union(x: number, y: number, value: number): void {
const [rootX, weightX] = this.find(x); // x = weightX × rootX
const [rootY, weightY] = this.find(y); // y = weightY × rootY
if (rootX === rootY) return; // 已在同一集合
// 推導:x / y = value → weightX × rootX / (weightY × rootY) = value
// 令 rootX = (value × weightY / weightX) × rootY
this.parent[rootX] = rootY;
this.weight[rootX] = value * weightY / weightX;
}
// 查詢 x / y 的值,返回 -1 表示不連通
query(x: number, y: number): number {
const [rootX, weightX] = this.find(x);
const [rootY, weightY] = this.find(y);
if (rootX !== rootY) return -1;
return weightX / weightY;
}
}
C++ 對照實作
#include <bits/stdc++.h>
using namespace std;
// ===== 標準 UnionFind(陣列實作,效率最高)=====
class UnionFind {
vector<int> parent, rank_;
int count_; // 連通分量數
public:
explicit UnionFind(int n) : parent(n), rank_(n, 0), count_(n) {
iota(parent.begin(), parent.end(), 0); // parent[i] = i
}
int find(int x) {
// 路徑壓縮(迭代版)
int root = x;
while (parent[root] != root) root = parent[root];
while (parent[x] != root) {
int next = parent[x];
parent[x] = root;
x = next;
}
return root;
}
// 返回是否成功合併(false = 已連通)
bool unite(int x, int y) {
int rx = find(x), ry = find(y);
if (rx == ry) return false;
if (rank_[rx] < rank_[ry]) swap(rx, ry);
parent[ry] = rx;
if (rank_[rx] == rank_[ry]) rank_[rx]++;
count_--;
return true;
}
bool connected(int x, int y) { return find(x) == find(y); }
int count() const { return count_; }
};
// ===== 模板化 UnionFind(支援任意可雜湊型別為節點 ID)=====
template<typename T>
class UnionFindMap {
unordered_map<T, T> parent;
unordered_map<T, int> rank_;
int count_ = 0;
public:
void add(const T& x) {
if (parent.count(x)) return;
parent[x] = x;
rank_[x] = 0;
count_++;
}
T find(const T& x) {
if (parent.at(x) != x) {
parent.at(x) = find(parent.at(x)); // 遞迴路徑壓縮
}
return parent.at(x);
}
bool unite(const T& x, const T& y) {
T rx = find(x), ry = find(y);
if (rx == ry) return false;
if (rank_[rx] < rank_[ry]) swap(rx, ry);
parent[ry] = rx;
if (rank_[rx] == rank_[ry]) rank_[rx]++;
count_--;
return true;
}
bool connected(const T& x, const T& y) { return find(x) == find(y); }
int count() const { return count_; }
};
複雜度分析
| 操作 | 未優化 | 路徑壓縮 only | 按秩合併 only | 兩者同時 |
|---|---|---|---|---|
| Find | O(n) worst | O(log n) amortized | O(log n) worst | O(α(n)) amortized |
| Union | O(n) worst | O(log n) amortized | O(log n) worst | O(α(n)) amortized |
| 初始化 | O(n) | O(n) | O(n) | O(n) |
| 空間 | O(n) | O(n) | O(n) | O(n) |
逆 Ackermann 函數 α(n)
α(n)(逆 Ackermann 函數) 是 Ackermann 函數的反函數,增長速度極其緩慢:
| n | α(n) |
|---|---|
| 1 | 0 |
| 4 | 1 |
| 16 | 2 |
| 65,536 | 3 |
| 2^65536 | 4 |
對任何現實中可能出現的 n,α(n) ≤ 4。因此路徑壓縮 + 按秩合併的實際效果等同於常數時間。
這是理論電腦科學中少數被證明的精確下界——沒有任何 Union-Find 演算法能在最壞情況下比 O(α(n)) 更快(Tarjan, 1975)。
變體與延伸
按大小合併(Union by Size)
按大小(Union by Size) 是按秩合併的替代方案:用 size[i] 記錄每棵樹的節點數,合併時永遠把節點數少的樹掛在節點數多的樹下。
按大小合併的好處是 size 陣列的語義比 rank 更直觀(rank 引入路徑壓縮後不再是精確樹高),且同樣能保證 O(log n) worst-case。
// Union by Size 版本
class UnionFindBySize {
private parent: number[];
private size: number[]; // 每棵樹的節點數
constructor(n: number) {
this.parent = Array.from({ length: n }, (_, i) => i);
this.size = new Array(n).fill(1); // 初始每棵樹只有 1 個節點
}
find(x: number): number {
while (this.parent[x] !== x) {
this.parent[x] = this.parent[this.parent[x]]; // 路徑減半(Path Halving)
x = this.parent[x];
}
return x;
}
union(x: number, y: number): boolean {
const rootX = this.find(x);
const rootY = this.find(y);
if (rootX === rootY) return false;
// 將小樹掛在大樹下
if (this.size[rootX] < this.size[rootY]) {
this.parent[rootX] = rootY;
this.size[rootY] += this.size[rootX];
} else {
this.parent[rootY] = rootX;
this.size[rootX] += this.size[rootY];
}
return true;
}
}
可撤銷併查集(Rollback DSU)
標準路徑壓縮是不可撤銷的,若需支援撤銷 Union(如離線動態圖問題),必須捨棄路徑壓縮,只保留按秩合併,並用 Stack 記錄每次修改:
Union(x, y) 時:
記錄 (rootX, oldRankX, rootY, oldRankY) → 推入 Stack
Rollback() 時:
從 Stack 彈出,還原 parent 與 rank
應用場景:
- 離線動態圖的橋/割點查詢
- 分治 + 併查集(Divide and Conquer + DSU on tree)
- 時光旅行查詢(Time-travel queries)
時間複雜度退化至 O(log n),但換來了可撤銷能力。
持久化併查集(Persistent DSU)
使用**持久化陣列(Persistent Array,基於可持久化線段樹實作)**取代普通陣列儲存 parent 與 rank,使每個歷史版本都能 O(log n) 查詢。空間複雜度 O(n + Q log n),時間複雜度 O(Q log n),適合需要查詢歷史版本連通性的問題。
面試考點
常見陷阱
1. 忘記初始化 parent[i] = i
併查集的每個節點必須初始指向自身。若 parent 陣列全為 0,Find 會錯誤地把所有節點的根返回為 0。
2. rank 不是精確樹高
引入路徑壓縮後,rank 只是樹高的上界,不能用 rank 計算精確高度。若需精確追蹤集合大小,應改用 size 陣列。
3. union 返回值的遺漏
在需要偵測環(如 LeetCode 684)或計算連通分量數時,必須判斷 union 的返回值。直接呼叫而不檢查,count 減少邏輯會出錯。
4. 節點編號從 0 還是從 1
LeetCode 題目的節點通常從 1 開始,應建立大小 n+1 的 parent 陣列,或統一偏移,否則越界或根節點錯誤。
5. 帶權併查集的權值方向混淆
定義 weight[x] 為「x 相對於 parent[x] 的倍數」時,路徑壓縮中累積倍數的方向必須正確。方向弄反,查詢結果出錯。
應用場景速查
| 問題類型 | 解法提示 |
|---|---|
| 圖的連通分量數 | 初始化 count = n,每次合併成功 count– |
| 判斷圖中是否有環 | union 返回 false → 兩端點已連通 → 有環 |
| 最小生成樹(Kruskal) | 排序邊,依序嘗試 union,跳過已連通的邊 |
| 帳號合併 / 好友圈 | 以共同屬性(email)為節點,同一來源全部 union |
| 動態連通性查詢 | union-find 優於 DFS/BFS,尤其動態更新圖 |
LeetCode 精選練習
LeetCode 200 — Number of Islands
function numIslands(grid: string[][]): number {
const rows = grid.length, cols = grid[0].length;
// 二維座標 (r, c) 映射到一維索引
const idx = (r: number, c: number) => r * cols + c;
// 初始化:只為陸地節點建立 parent
let landCount = 0;
const parent: number[] = new Array(rows * cols).fill(-1);
const rank: number[] = new Array(rows * cols).fill(0);
for (let r = 0; r < rows; r++) {
for (let c = 0; c < cols; c++) {
if (grid[r][c] === '1') {
const i = idx(r, c);
parent[i] = i; // 陸地格子才加入併查集
landCount++; // 每個陸地格子初始為獨立連通分量
}
}
}
function find(x: number): number {
if (parent[x] !== x) parent[x] = find(parent[x]); // 路徑壓縮
return parent[x];
}
function union(x: number, y: number): void {
const rx = find(x), ry = find(y);
if (rx === ry) return;
if (rank[rx] < rank[ry]) { parent[rx] = ry; }
else if (rank[rx] > rank[ry]) { parent[ry] = rx; }
else { parent[ry] = rx; rank[rx]++; }
landCount--; // 合併兩個陸地,連通分量數減一
}
// 只向右、向下合併(避免重複處理)
const dirs = [[0, 1], [1, 0]];
for (let r = 0; r < rows; r++) {
for (let c = 0; c < cols; c++) {
if (grid[r][c] === '1') {
for (const [dr, dc] of dirs) {
const nr = r + dr, nc = c + dc;
if (nr < rows && nc < cols && grid[nr][nc] === '1') {
union(idx(r, c), idx(nr, nc));
}
}
}
}
}
return landCount;
// 時間複雜度:O(M × N × α(M × N)) ≈ O(M × N)
// 空間複雜度:O(M × N)
}
LeetCode 684 — Redundant Connection
// 在無向圖中找出第一條形成環的多餘邊
// 策略:依序處理邊,若兩端點已連通,則此邊多餘
function findRedundantConnection(edges: number[][]): number[] {
const n = edges.length; // 節點編號 1 到 n
const parent = Array.from({ length: n + 1 }, (_, i) => i);
const rank = new Array(n + 1).fill(0);
function find(x: number): number {
if (parent[x] !== x) parent[x] = find(parent[x]); // 路徑壓縮
return parent[x];
}
function union(x: number, y: number): boolean {
// 返回 false 表示已連通(此邊多餘)
const rx = find(x), ry = find(y);
if (rx === ry) return false;
if (rank[rx] < rank[ry]) { parent[rx] = ry; }
else if (rank[rx] > rank[ry]) { parent[ry] = rx; }
else { parent[ry] = rx; rank[rx]++; }
return true;
}
for (const [u, v] of edges) {
if (!union(u, v)) {
return [u, v]; // 此邊兩端已連通,加入會形成環
}
}
return []; // 題目保證有多餘邊,理論上不到此行
// 時間複雜度:O(N × α(N)) ≈ O(N)
// 空間複雜度:O(N)
}
LeetCode 547 — Number of Provinces
// 給定 n×n 鄰接矩陣 isConnected,返回省份數(連通分量數)
function findCircleNum(isConnected: number[][]): number {
const n = isConnected.length;
const parent = Array.from({ length: n }, (_, i) => i);
const rank = new Array(n).fill(0);
let count = n; // 初始 n 個省份
function find(x: number): number {
if (parent[x] !== x) parent[x] = find(parent[x]);
return parent[x];
}
function union(x: number, y: number): void {
const rx = find(x), ry = find(y);
if (rx === ry) return;
if (rank[rx] < rank[ry]) { parent[rx] = ry; }
else if (rank[rx] > rank[ry]) { parent[ry] = rx; }
else { parent[ry] = rx; rank[rx]++; }
count--;
}
for (let i = 0; i < n; i++) {
for (let j = i + 1; j < n; j++) {
if (isConnected[i][j] === 1) {
union(i, j);
}
}
}
return count;
// 時間複雜度:O(n² × α(n)) ≈ O(n²)
}
LeetCode 721 — Accounts Merge
// 策略:
// 1. 為每個 email 分配數字 ID,建立 email → ID 映射
// 2. 同一帳號的所有 email 執行 Union(以第一個 email 為代表連接其餘)
// 3. 以根節點 ID 分組,還原每個連通集合的 email 列表
function accountsMerge(accounts: string[][]): string[][] {
const emailToId = new Map<string, number>();
const emailToName = new Map<string, string>();
let idCounter = 0;
for (const account of accounts) {
const name = account[0];
for (let i = 1; i < account.length; i++) {
const email = account[i];
if (!emailToId.has(email)) {
emailToId.set(email, idCounter++);
emailToName.set(email, name);
}
}
}
const parent = Array.from({ length: idCounter }, (_, i) => i);
const rank = new Array(idCounter).fill(0);
function find(x: number): number {
if (parent[x] !== x) parent[x] = find(parent[x]);
return parent[x];
}
function union(x: number, y: number): void {
const rx = find(x), ry = find(y);
if (rx === ry) return;
if (rank[rx] >= rank[ry]) {
parent[ry] = rx;
if (rank[rx] === rank[ry]) rank[rx]++;
} else {
parent[rx] = ry;
}
}
// 同一帳號的 email 全部合併
for (const account of accounts) {
if (account.length < 2) continue;
const firstId = emailToId.get(account[1])!;
for (let i = 2; i < account.length; i++) {
union(firstId, emailToId.get(account[i])!);
}
}
// 按根節點 ID 分組 email
const rootToEmails = new Map<number, string[]>();
for (const [email, id] of emailToId) {
const root = find(id);
if (!rootToEmails.has(root)) rootToEmails.set(root, []);
rootToEmails.get(root)!.push(email);
}
// 構建結果:[帳號名稱, ...排序後的 emails]
const result: string[][] = [];
for (const [root, emails] of rootToEmails) {
emails.sort();
const name = emailToName.get(emails[0])!;
result.push([name, ...emails]);
}
return result;
// 時間複雜度:O(N×K×α(N×K) + N×K×log(K)),瓶頸在排序
// 空間複雜度:O(N × K)
}
LeetCode 990 — Satisfiability of Equality Equations
// 給定等式字串陣列("a==b" 或 "a!=b"),判斷是否所有等式都能同時成立
// 策略:先處理所有等式(union),再驗證所有不等式(connected 應為 false)
function equationsPossible(equations: string[]): boolean {
const parent = Array.from({ length: 26 }, (_, i) => i);
function find(x: number): number {
if (parent[x] !== x) parent[x] = find(parent[x]);
return parent[x];
}
function union(x: number, y: number): void {
const rx = find(x), ry = find(y);
if (rx !== ry) parent[rx] = ry;
}
// 第一遍:處理所有 "==" 等式
for (const eq of equations) {
if (eq[1] === '=') {
union(eq.charCodeAt(0) - 97, eq.charCodeAt(3) - 97);
}
}
// 第二遍:驗證所有 "!=" 不等式
for (const eq of equations) {
if (eq[1] === '!') {
const a = eq.charCodeAt(0) - 97;
const b = eq.charCodeAt(3) - 97;
if (find(a) === find(b)) return false; // 矛盾:a!=b 但 find 相同
}
}
return true;
// 時間複雜度:O(N × α(26)) ≈ O(N)
// 空間複雜度:O(26) = O(1)
}
精選題目速查
| 題號 | 題目 | 難度 | 核心技巧 |
|---|---|---|---|
| 200 | Number of Islands | Medium | 陸地格子 union,landCount 計算 |
| 547 | Number of Provinces | Medium | 直接建 n 節點 UF,返回 count |
| 684 | Redundant Connection | Medium | union 返回 false → 冗餘邊 |
| 721 | Accounts Merge | Medium | email 為節點,合併同帳號 |
| 990 | Satisfiability of Equality Equations | Medium | 先處理等式,再驗證不等式 |
總結
併查集(Union-Find) 用一個幾乎不花空間的陣列(parent + rank),實現了動態連通性問題的近乎最優解。兩大核心優化:
- 路徑壓縮:Find 時把路徑上所有節點直接指向根,讓後續查詢只需一步
- 按秩合併:Union 時把矮樹掛在高樹下,防止退化成鏈
兩者結合後,n 次操作的攤銷時間複雜度為 O(n × α(n)),其中 α 是增長極其緩慢的逆 Ackermann 函數,對任何實際輸入都不超過 4——換言之,接近常數時間。
在面試中,Union-Find 解法最直覺的標誌是**「動態加邊 + 頻繁查詢連通性」**的問題。學會辨識這個模式,能讓你在 200、547、684、721、990 等題目上輕鬆拿分。
希望這篇文章能幫助你徹底掌握 Union-Find 的設計思路與實作細節。如有任何問題,歡迎透過 Contact 頁面 聯絡我。
下一篇預告:線段樹(Segment Tree)——區間查詢與單點更新的核心武器,帶你深入理解 O(log n) 區間操作的原理與實作。