字典樹 Trie — 前綴搜尋與自動補全的核心資料結構 | 資料結構與演算法
字典樹(Trie,又稱前綴樹) 是一種專門為字串集合設計的多路樹資料結構,以極高的效率支援前綴查詢(Prefix Query)。插入、搜尋、前綴匹配的時間複雜度皆為 O(L)(L 為字串長度),完全不受字典大小影響。理解 Trie 是掌握搜尋引擎自動補全、拼字檢查與路由演算法的關鍵。
前言
想像你在手機上打 “ap”,輸入法立刻推薦 “apple”、“application”、“apply”——這背後是什麼魔法?
答案是 Trie。
如果用 HashMap 存所有單詞,每次前綴搜尋都需要遍歷整個字典;如果用排序陣列加二分搜尋,也要 O(log n × L) 的時間。但 Trie 把字串的每個字元作為樹的一層,共享相同前綴的字串走同一條路徑——搜尋前綴 “ap” 只需走兩步,就能找到所有以 “ap” 開頭的詞。
本文學習要點:
- Trie 節點結構與前綴共享原理
- 三大核心操作:
insert、search、startsWith - TypeScript 完整實作(含
delete、自動補全) - C++ 陣列 vs HashMap 雙實作對照
- 壓縮 Trie(Radix Tree)、XOR Trie、Suffix Trie 延伸
- 五大面試考點與 LeetCode 五道精選題
核心概念
Trie 節點結構
Trie 的每個節點只需兩個欄位:
TrieNode {
children: Map<char, TrieNode> // 子節點映射,key 為字元
isEnd: boolean // 此節點是否為某個字串的結尾
}
節點本身不儲存字元——字元隱含在父節點到此節點的**邊(edge)**上。從根節點到任一節點的路徑,串起來就是對應的字串前綴。
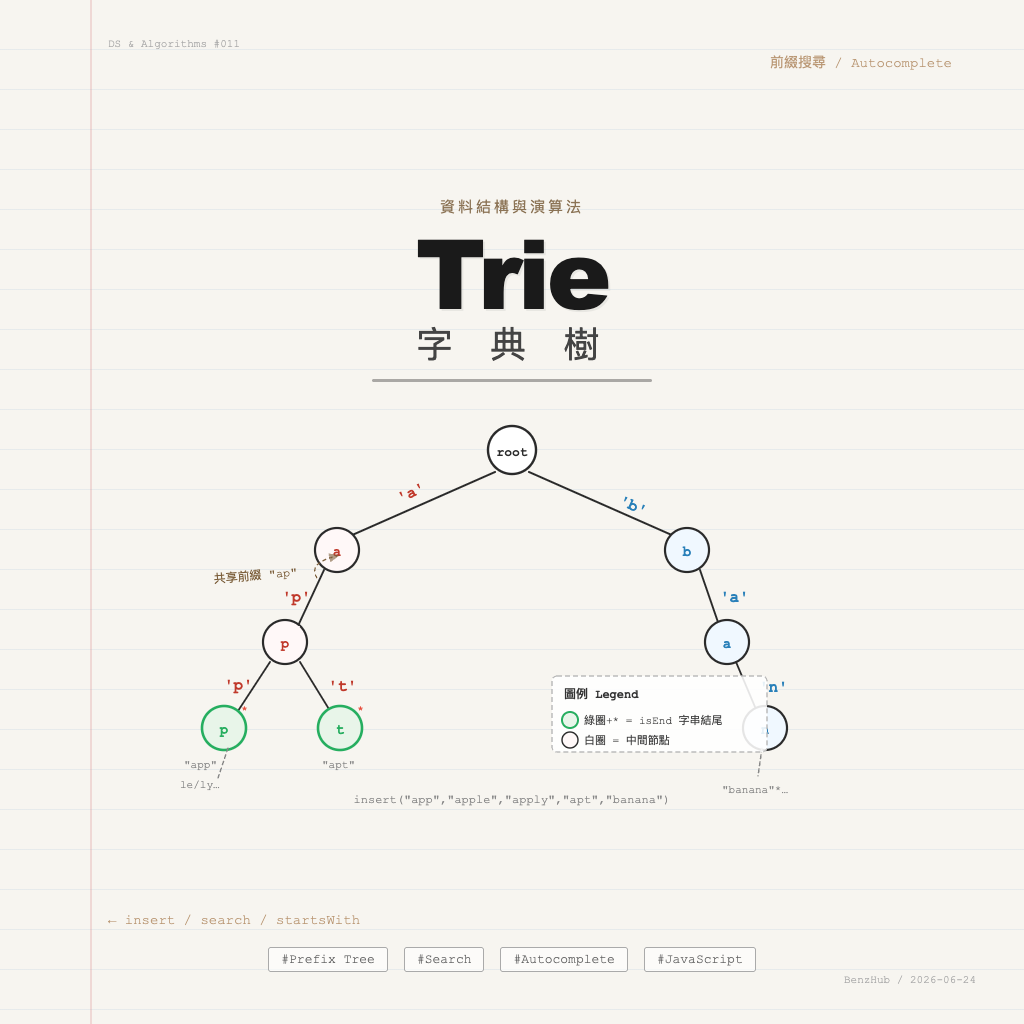
前綴共享原理
Trie 的精髓是「共享前綴,節省空間」。插入 “apple”、“app”、“apply”、“apt”、“banana” 後的樹結構:
[root]
/ \
'a' 'b'
| |
'p' 'a'
/ \ |
'p' 't' 'n'
|* |* |
'l' (end) 'a'
/ \ |
'e' 'y' 'n'
|* |* |
(end) (end) 'a'
|*
(end)
標記 * = isEnd = true
"app" → root→a→p→p*
"apple" → root→a→p→p→l→e*
"apply" → root→a→p→p→l→y*
"apt" → root→a→p→t*
"banana"→ root→b→a→n→a→n→a*
“apple”、“apply”、“app” 全部共用 root→a→p→p 這段路徑,只在 p 節點之後才分叉。這正是 Trie 能在 O(L) 完成前綴查詢的原因。
三大核心操作
insert(word):逐字元遍歷,若子節點不存在則新建,遍歷完成後將最後節點的 isEnd 設為 true。
search(word):逐字元遍歷,若中途找不到對應子節點則返回 false,遍歷完成後返回當前節點的 isEnd 值(必須是完整單詞,不能只是前綴)。
startsWith(prefix):與 search 邏輯相同,但遍歷完成後只要節點存在即返回 true,不檢查 isEnd。前綴存在就算符合。
JavaScript / TypeScript 實作
基礎 Trie 類別(insert / search / startsWith / delete)
class TrieNode {
children: Map<string, TrieNode>;
isEnd: boolean;
constructor() {
this.children = new Map();
this.isEnd = false;
}
}
class Trie {
private root: TrieNode;
constructor() {
this.root = new TrieNode();
}
// ─── 插入:O(L) ───────────────────────────────────────────────────────────
insert(word: string): void {
let node = this.root;
for (const ch of word) {
if (!node.children.has(ch)) {
node.children.set(ch, new TrieNode());
}
node = node.children.get(ch)!;
}
node.isEnd = true;
}
// ─── 搜尋(完整單詞):O(L) ───────────────────────────────────────────────
search(word: string): boolean {
const node = this._traverse(word);
return node !== null && node.isEnd; // 必須到達且是完整字串結尾
}
// ─── 前綴匹配:O(L) ────────────────────────────────────────────────────────
startsWith(prefix: string): boolean {
return this._traverse(prefix) !== null; // 節點存在即可,不需要 isEnd
}
private _traverse(str: string): TrieNode | null {
let node = this.root;
for (const ch of str) {
if (!node.children.has(ch)) return null;
node = node.children.get(ch)!;
}
return node;
}
// ─── 刪除:後序遞迴,清理只有此字串使用的孤立節點 ─────────────────────────
delete(word: string): boolean {
return this._delete(this.root, word, 0);
}
private _delete(node: TrieNode, word: string, depth: number): boolean {
if (depth === word.length) {
if (!node.isEnd) return false; // 字串不存在
node.isEnd = false;
return node.children.size === 0; // 無子節點,可刪除此節點
}
const ch = word[depth];
const child = node.children.get(ch);
if (!child) return false;
const shouldDelete = this._delete(child, word, depth + 1);
if (shouldDelete) {
node.children.delete(ch);
// 若此節點也不是其他字串結尾且無子節點,也可以被刪除
return !node.isEnd && node.children.size === 0;
}
return false;
}
}
// 使用範例
const trie = new Trie();
trie.insert("apple");
trie.insert("app");
trie.insert("apply");
console.log(trie.search("app")); // true("app" 是完整單詞)
console.log(trie.search("appl")); // false("appl" 未被插入)
console.log(trie.startsWith("app")); // true(前綴存在)
console.log(trie.startsWith("apt")); // false("apt" 未被插入)
trie.delete("app");
console.log(trie.search("app")); // false(已刪除)
console.log(trie.search("apple")); // true("apple" 仍存在)
自動補全(帶搜尋排名的 Top-K)
實務中的自動補全除了找出所有前綴符合的詞,還需要按「熱門程度」排序,只返回前 K 個結果。有兩種策略:
- 預計算 Top-K:插入時在每個前綴節點維護一個排序好的 Top-K 列表,查詢 O(P),但插入較慢。
- 即時 DFS:查詢時從前綴節點做 DFS 收集所有符合詞後再排序,查詢 O(P + R)(R 為所有結果總字元數)。
interface AutocompleteEntry {
word: string;
score: number; // 搜尋頻率或排名分數
}
class RankedTrieNode {
children: Map<string, RankedTrieNode>;
entries: AutocompleteEntry[]; // 此節點作為前綴時的 Top-K 結果(預計算)
isEnd: boolean;
score: number;
constructor() {
this.children = new Map();
this.entries = [];
this.isEnd = false;
this.score = 0;
}
}
class AutocompleteTrie {
private root: RankedTrieNode;
private readonly TOP_K = 3;
constructor() {
this.root = new RankedTrieNode();
}
// 插入帶分數的詞條,沿途更新每個前綴節點的 Top-K 列表
insert(word: string, score: number): void {
let node = this.root;
for (const ch of word) {
if (!node.children.has(ch)) {
node.children.set(ch, new RankedTrieNode());
}
node = node.children.get(ch)!;
this._updateTopK(node, { word, score });
}
node.isEnd = true;
node.score = score;
}
private _updateTopK(node: RankedTrieNode, entry: AutocompleteEntry): void {
const existing = node.entries.findIndex(e => e.word === entry.word);
if (existing >= 0) {
node.entries[existing].score = Math.max(node.entries[existing].score, entry.score);
} else {
node.entries.push(entry);
}
// 按分數降序,保留 Top-K
node.entries.sort((a, b) => b.score - a.score);
if (node.entries.length > this.TOP_K) {
node.entries.length = this.TOP_K;
}
}
// O(P) 時間直接返回預計算的 Top-K 結果
getTopK(prefix: string): AutocompleteEntry[] {
let node = this.root;
for (const ch of prefix) {
if (!node.children.has(ch)) return [];
node = node.children.get(ch)!;
}
return node.entries;
}
// 即時 DFS 版本:動態蒐集所有前綴下的詞條再排序
getSuggestionsLive(prefix: string): string[] {
let node = this.root;
for (const ch of prefix) {
if (!node.children.has(ch)) return [];
node = node.children.get(ch)!;
}
const results: AutocompleteEntry[] = [];
this._dfs(node, prefix, results);
results.sort((a, b) => b.score - a.score);
return results.slice(0, this.TOP_K).map(e => e.word);
}
private _dfs(node: RankedTrieNode, currentWord: string, results: AutocompleteEntry[]): void {
if (node.isEnd) {
results.push({ word: currentWord, score: node.score });
}
for (const [ch, child] of node.children) {
this._dfs(child, currentWord + ch, results);
}
}
}
// 使用範例:模擬搜尋引擎自動補全
const ac = new AutocompleteTrie();
ac.insert("apple", 100);
ac.insert("app", 80);
ac.insert("apply", 60);
ac.insert("apt", 40);
ac.insert("application", 120);
// 輸入 "app" 時返回前三名
console.log(ac.getTopK("app"));
// [{word:"application",score:120},{word:"apple",score:100},{word:"app",score:80}]
XOR Trie(最大 XOR 值)
XOR Trie 是 Trie 的位元變體,用於在整數集合中尋找最大 XOR 值的數對。每個整數以 32 位元二進制從最高位到最低位插入 Trie,查詢時貪婪選擇與當前位相反的子節點,使 XOR 結果每一位盡量為 1。
class XorTrieNode {
children: [XorTrieNode | null, XorTrieNode | null];
constructor() {
this.children = [null, null];
}
}
class XorTrie {
private root: XorTrieNode;
private readonly BITS = 31; // 覆蓋至多 2^31 - 1
constructor() {
this.root = new XorTrieNode();
}
insert(num: number): void {
let node = this.root;
for (let i = this.BITS; i >= 0; i--) {
const bit = (num >> i) & 1;
if (!node.children[bit]) {
node.children[bit] = new XorTrieNode();
}
node = node.children[bit]!;
}
}
// 查詢與 num 能產生最大 XOR 的值,返回最大 XOR 結果
maxXorWith(num: number): number {
let node = this.root;
let maxXor = 0;
for (let i = this.BITS; i >= 0; i--) {
const bit = (num >> i) & 1;
const want = 1 - bit; // 希望走相反位元使 XOR 為 1
if (node.children[want]) {
maxXor |= (1 << i);
node = node.children[want]!;
} else if (node.children[bit]) {
node = node.children[bit]!;
} else {
break;
}
}
return maxXor;
}
}
// LeetCode 421: Maximum XOR of Two Numbers in an Array
function findMaximumXOR(nums: number[]): number {
const trie = new XorTrie();
let result = 0;
for (const num of nums) {
trie.insert(num);
result = Math.max(result, trie.maxXorWith(num));
}
return result;
}
console.log(findMaximumXOR([3, 10, 5, 25, 2, 8])); // 28(5 XOR 25 = 28)
C++ 對照
陣列實作 vs HashMap 實作
#include <bits/stdc++.h>
using namespace std;
// ===== 方法一:陣列 children(純小寫英文,記憶體固定,存取快)=====
struct TrieNodeArray {
TrieNodeArray* children[26];
bool isEnd;
TrieNodeArray() : isEnd(false) {
fill(begin(children), end(children), nullptr);
}
~TrieNodeArray() {
for (auto* child : children) delete child;
}
};
class TrieArray {
TrieNodeArray* root;
public:
TrieArray() : root(new TrieNodeArray()) {}
~TrieArray() { delete root; }
void insert(const string& word) {
auto* node = root;
for (char ch : word) {
int idx = ch - 'a';
if (!node->children[idx]) {
node->children[idx] = new TrieNodeArray();
}
node = node->children[idx];
}
node->isEnd = true;
}
bool search(const string& word) const {
auto* node = traverse(word);
return node && node->isEnd;
}
bool startsWith(const string& prefix) const {
return traverse(prefix) != nullptr;
}
private:
TrieNodeArray* traverse(const string& str) const {
auto* node = root;
for (char ch : str) {
int idx = ch - 'a';
if (!node->children[idx]) return nullptr;
node = node->children[idx];
}
return node;
}
};
// ===== 方法二:HashMap children(支援任意字元集,靈活但常數較大)=====
struct TrieNodeMap {
unordered_map<char, TrieNodeMap*> children;
bool isEnd = false;
~TrieNodeMap() {
for (auto& [ch, child] : children) delete child;
}
};
class TrieMap {
TrieNodeMap* root;
public:
TrieMap() : root(new TrieNodeMap()) {}
~TrieMap() { delete root; }
void insert(const string& word) {
auto* node = root;
for (char ch : word) {
if (!node->children.count(ch)) {
node->children[ch] = new TrieNodeMap();
}
node = node->children[ch];
}
node->isEnd = true;
}
bool search(const string& word) const {
auto* node = traverse(word);
return node && node->isEnd;
}
bool startsWith(const string& prefix) const {
return traverse(prefix) != nullptr;
}
// 支援萬用字元 '.' 的搜尋(對應 LeetCode 211)
bool searchWithDot(const string& word) const {
return searchHelper(root, word, 0);
}
private:
TrieNodeMap* traverse(const string& str) const {
auto* node = root;
for (char ch : str) {
auto it = node->children.find(ch);
if (it == node->children.end()) return nullptr;
node = it->second;
}
return node;
}
bool searchHelper(TrieNodeMap* node, const string& word, int idx) const {
if (!node) return false;
if (idx == (int)word.size()) return node->isEnd;
char ch = word[idx];
if (ch == '.') {
// 萬用字元:嘗試所有子節點
for (auto& [c, child] : node->children) {
if (searchHelper(child, word, idx + 1)) return true;
}
return false;
}
auto it = node->children.find(ch);
if (it == node->children.end()) return false;
return searchHelper(it->second, word, idx + 1);
}
};
// ===== 兩種實作的對照 =====
// 特性 陣列實作 HashMap 實作
// 字元範圍 固定(如小寫 26) 任意字元集
// 每節點記憶體 固定 26 × pointer 動態,按實際子節點
// 子節點存取 O(1) 直接索引 O(1) 平均,但有常數開銷
// 快取友好性 較好(連續陣列) 較差(散亂指針)
// 適合場景 競賽、純英文字串 生產環境、Unicode 支援
複雜度分析
| 操作 | 時間複雜度 | 空間複雜度 | 說明 |
|---|---|---|---|
| insert | O(L) | O(L × Σ) | L = 字串長,Σ = 字母表大小 |
| search | O(L) | O(1) | 只讀,不額外分配空間 |
| startsWith | O(L) | O(1) | 前綴匹配,不需要 isEnd |
| delete | O(L) | O(1) | 需後序遞迴清理孤立節點 |
| 自動補全列舉 | O(P + R) | O(R) | P = 前綴長,R = 結果總字元數 |
| XOR 最大值查詢 | O(W) | O(N × W) | W = 位元寬,N = 整數個數 |
空間使用比較:
- HashMap children:靈活,適合稀疏字母表(Unicode),但有額外 HashMap 開銷。
- 陣列 children(大小 26):每節點固定 26 個指針,適合純小寫英文字母,存取 O(1) 且快取友好。
Trie vs HashMap:HashMap 的精確查詢平均 O(1),但不支援前綴搜尋。Trie 的所有操作均為 O(L)(L 為字串長),且天然支援前綴匹配、自動補全、字典序遍歷。需要前綴相關操作就選 Trie。
變體與延伸
壓縮 Trie(Radix Tree / Patricia Trie)
標準 Trie 中,若某條路徑只有單一子節點(且不是字串結尾),會形成長鏈浪費節點。壓縮 Trie(Radix Tree) 將這些單鏈路徑合併為邊上的字串標籤:
標準 Trie(插入 "interview", "internal", "integer")
root→i→n→t→e→r→v→i→e→w* (interview)
|
r→n→a→l* (internal)
|
e→g→e→r* (integer)
壓縮 Trie(Radix Tree)
root→"int"→"e"→"r"→"view"* (interview)
|
"rnal"* (internal)
|
"eger"* (integer)
優點:節點數從 O(總字元數) 降至 O(字串數)
Patricia Trie 是壓縮 Trie 的一種實作,每個節點儲存一個整數索引(bit position),用於指示下次分支判斷應看哪一位。IP 路由表的最長前綴匹配(Longest Prefix Match)通常用這種結構。
XOR Trie(最大 XOR 對)
XOR Trie 用於在整數集合中尋找最大 XOR 值的數對。每個整數以 32 位元二進制從最高位到最低位插入 Trie,查詢時貪婪選擇相反位元:
插入 3 (011), 5 (101), 10 (1010), 14 (1110) 到 XOR Trie(4-bit)
查詢 q=14 (1110) 的最大 XOR 對:
bit3: q=1,想選 0 → 有 0 子節點 → 走 0,XOR 貢獻 1
bit2: q=1,想選 0 → 有 0 子節點 → 走 0,XOR 貢獻 1
bit1: q=1,想選 0 → 有 0 子節點 → 走 0,XOR 貢獻 1
bit0: q=0,想選 1 → 有 1 子節點 → 走 1,XOR 貢獻 1
結果:14 XOR 1 = 15(最大 XOR)
Suffix Trie / Suffix Array
對字串所有後綴建立 Trie(Suffix Trie),可在 O(P) 時間查詢任意子字串是否存在。壓縮版本(Suffix Array + LCP Array)空間效率更高,廣泛應用於 DNA 序列比對、全文搜尋引擎。
Ternary Search Tree(TST)
TST 是 Trie 與二元搜尋樹的結合:每節點有三個子節點(左、中、右),代表當前字元「小於」、「等於」、「大於」三種情況。記憶體比固定陣列 Trie 節省,但搜尋複雜度退化為 O(L log Σ)。
面試考點
常見陷阱一:忘記設置 isEnd
insert 完成後,若未將最後節點的 isEnd 設為 true,search 永遠返回 false。
// 錯誤:忘記 isEnd
function insertWrong(root: TrieNode, word: string): void {
let node = root;
for (const ch of word) {
if (!node.children.has(ch)) node.children.set(ch, new TrieNode());
node = node.children.get(ch)!;
}
// 忘記這行!
// node.isEnd = true;
}
// 此後 search("word") 永遠返回 false
常見陷阱二:search 與 startsWith 混淆
search("app") 需要 isEnd === true(“app” 必須是完整單詞)。
startsWith("app") 只要節點存在即可,不需要 isEnd。
常見錯誤是在 startsWith 中也加上 isEnd 判斷,導致前綴查詢失效。
// 錯誤的 startsWith
startsWith_WRONG(prefix: string): boolean {
const node = this._traverse(prefix);
return node !== null && node.isEnd; // 多了 && node.isEnd!
// 如果 "app" 不是字串結尾,startsWith("ap") 就會錯誤返回 false
}
常見陷阱三:XOR Trie 的位元順序
必須從最高位元向最低位元插入,否則貪婪策略從低位決策,無法最大化高位貢獻。
// 錯誤:從低位開始
for (let i = 0; i <= this.BITS; i++) { ... } // 錯誤
// 正確:從高位開始
for (let i = this.BITS; i >= 0; i--) { ... } // 正確
常見陷阱四:Word Search II 的重複結果
同一個字串在 board 中可能有多條路徑匹配,需在找到後立即清除 Trie 中的 isEnd 標記,防止重複加入結果列表。
LeetCode 練習
LeetCode 208 — Implement Trie(Medium)
直接使用上方 Trie 類別即可,重點在 search 必須檢查 isEnd,startsWith 不需要。
class Trie208 {
private root: TrieNode;
constructor() { this.root = new TrieNode(); }
insert(word: string): void {
let node = this.root;
for (const ch of word) {
if (!node.children.has(ch)) node.children.set(ch, new TrieNode());
node = node.children.get(ch)!;
}
node.isEnd = true;
}
search(word: string): boolean {
let node = this.root;
for (const ch of word) {
if (!node.children.has(ch)) return false;
node = node.children.get(ch)!;
}
return node.isEnd; // 必須是完整單詞
}
startsWith(prefix: string): boolean {
let node = this.root;
for (const ch of prefix) {
if (!node.children.has(ch)) return false;
node = node.children.get(ch)!;
}
return true; // 節點存在即可
}
}
// 時間 O(L) per operation,空間 O(N × L)
LeetCode 211 — Design Add and Search Words(Medium)
支援萬用字元 '.' 的 Trie 搜尋,'.' 可以匹配任意單個字母,需要遞迴 DFS 嘗試所有子節點:
class WordDictionary {
private root: TrieNode;
constructor() { this.root = new TrieNode(); }
addWord(word: string): void {
let node = this.root;
for (const ch of word) {
if (!node.children.has(ch)) node.children.set(ch, new TrieNode());
node = node.children.get(ch)!;
}
node.isEnd = true;
}
search(word: string): boolean {
return this._dfs(this.root, word, 0);
}
private _dfs(node: TrieNode, word: string, idx: number): boolean {
if (idx === word.length) return node.isEnd;
const ch = word[idx];
if (ch === '.') {
// 萬用字元:嘗試所有子節點
for (const child of node.children.values()) {
if (this._dfs(child, word, idx + 1)) return true;
}
return false;
}
if (!node.children.has(ch)) return false;
return this._dfs(node.children.get(ch)!, word, idx + 1);
}
}
// 時間 O(L) 一般情況,最壞 O(Σ^L)(全萬用字元)
LeetCode 212 — Word Search II(Hard)
將所有 words 建入 Trie,在 board 上 DFS 的同時沿 Trie 走——遇到 isEnd 即收錄,並立刻清除避免重複:
function findWords(board: string[][], words: string[]): string[] {
// 建立 Trie
const root = new TrieNode();
for (const word of words) {
let node = root;
for (const ch of word) {
if (!node.children.has(ch)) node.children.set(ch, new TrieNode());
node = node.children.get(ch)!;
}
node.isEnd = true;
(node as any).word = word; // 在葉節點儲存完整字串,避免回溯重建
}
const rows = board.length, cols = board[0].length;
const result: string[] = [];
function dfs(r: number, c: number, node: TrieNode): void {
if (r < 0 || r >= rows || c < 0 || c >= cols) return;
const ch = board[r][c];
if (ch === '#' || !node.children.has(ch)) return; // '#' 表示已訪問
const nextNode = node.children.get(ch)!;
if (nextNode.isEnd) {
result.push((nextNode as any).word);
nextNode.isEnd = false; // 防止重複添加(關鍵!)
}
board[r][c] = '#'; // 標記已訪問
dfs(r + 1, c, nextNode);
dfs(r - 1, c, nextNode);
dfs(r, c + 1, nextNode);
dfs(r, c - 1, nextNode);
board[r][c] = ch; // 回溯
// 剪枝:若此節點已無子節點且非結尾,從父節點移除加速後續搜尋
if (nextNode.children.size === 0 && !nextNode.isEnd) {
node.children.delete(ch);
}
}
for (let r = 0; r < rows; r++) {
for (let c = 0; c < cols; c++) {
dfs(r, c, root);
}
}
return result;
}
// 時間 O(M × 4 × 3^(L-1)),M = board 格子數,L = 最長字串長
// 空間 O(N × L) for Trie,N = words 數,L = 平均長度
LeetCode 421 — Maximum XOR of Two Numbers in an Array(Medium)
XOR Trie 貪婪策略,從最高位到最低位逐步選擇與當前位相反的子節點:
function findMaximumXOR(nums: number[]): number {
const trie = new XorTrie(); // 使用上方 XorTrie 實作
let result = 0;
// 先全部插入,再全部查詢(a XOR b = b XOR a,順序不影響結果)
for (const num of nums) trie.insert(num);
for (const num of nums) {
result = Math.max(result, trie.maxXorWith(num));
}
return result;
}
// 時間 O(N × 32),空間 O(N × 32)
// 替代解法:位元遮罩(Bit Masking)+ HashSet,時空複雜度相同但無需 Trie 類別
function findMaximumXOR_bitMask(nums: number[]): number {
let maxXor = 0, mask = 0;
for (let i = 31; i >= 0; i--) {
mask |= (1 << i);
const prefixes = new Set(nums.map(n => n & mask));
const candidate = maxXor | (1 << i);
let found = false;
for (const prefix of prefixes) {
if (prefixes.has(candidate ^ prefix)) { found = true; break; }
}
if (found) maxXor = candidate;
}
return maxXor;
}
LeetCode 648 — Replace Words(Medium)
字典中有詞根(root),將句子中所有能被詞根替換的詞替換為最短詞根:
function replaceWords(dictionary: string[], sentence: string): string {
// 建立詞根 Trie
const root = new TrieNode();
for (const root_word of dictionary) {
let node = root;
for (const ch of root_word) {
if (!node.children.has(ch)) node.children.set(ch, new TrieNode());
node = node.children.get(ch)!;
}
node.isEnd = true;
(node as any).word = root_word;
}
return sentence.split(' ').map(word => {
let node = root;
for (const ch of word) {
if (!node.children.has(ch)) break;
node = node.children.get(ch)!;
if (node.isEnd) return (node as any).word; // 找到最短詞根,立即替換
}
return word; // 無詞根匹配,保留原詞
}).join(' ');
}
// 範例:dictionary=["cat","bat","rat"], sentence="the cattle was rattled by the battery"
// 輸出:"the cat was rat by the bat"
// 時間 O(N × L),N = 詞數,L = 詞長
總結
字典樹 Trie 是「以空間換時間」的典型代表——用多叉樹的結構共享前綴,讓所有字串操作只需 O(L) 時間,且天然支援前綴搜尋、自動補全等 HashMap 做不到的功能。回顧本文核心知識點:
節點結構:每個節點只需
children(子節點映射)和isEnd(是否是字串結尾),字元隱含在邊上,不存在節點本身。三大操作:
insert逐字元新建節點,search遍歷後檢查isEnd,startsWith遍歷後只要節點存在即返回true。這三者的時間複雜度均為 O(L)。實作選擇:純小寫英文用陣列(26 個槽位,存取快、快取友好);需要 Unicode 或動態字元集用 Map(靈活但有 HashMap 開銷)。
進階變體:壓縮 Trie(Radix Tree)節省記憶體;XOR Trie 解決最大 XOR 對問題;Suffix Trie 支援子字串快速查詢。
四大陷阱:忘記設
isEnd、混淆search與startsWith、XOR Trie 位元方向錯誤、Word Search II 重複收錄同一單詞。
掌握 Trie,你就掌握了自動補全、拼字檢查、IP 路由等無數系統設計題的核心元件。希望這篇文章能幫助你建立清晰的前綴樹思維,在面試中自信地應對各種字串題。如果有任何問題或疑惑,歡迎至 聯絡頁面 留言交流。
下一篇預告:我們將進入 併查集(Union-Find) 的世界,探討如何用近乎 O(1) 的效率解決動態連通性問題,以及在圖論中的廣泛應用。