雜湊表 — Hash Table 原理、碰撞處理與實作完整指南 | 資料結構與演算法
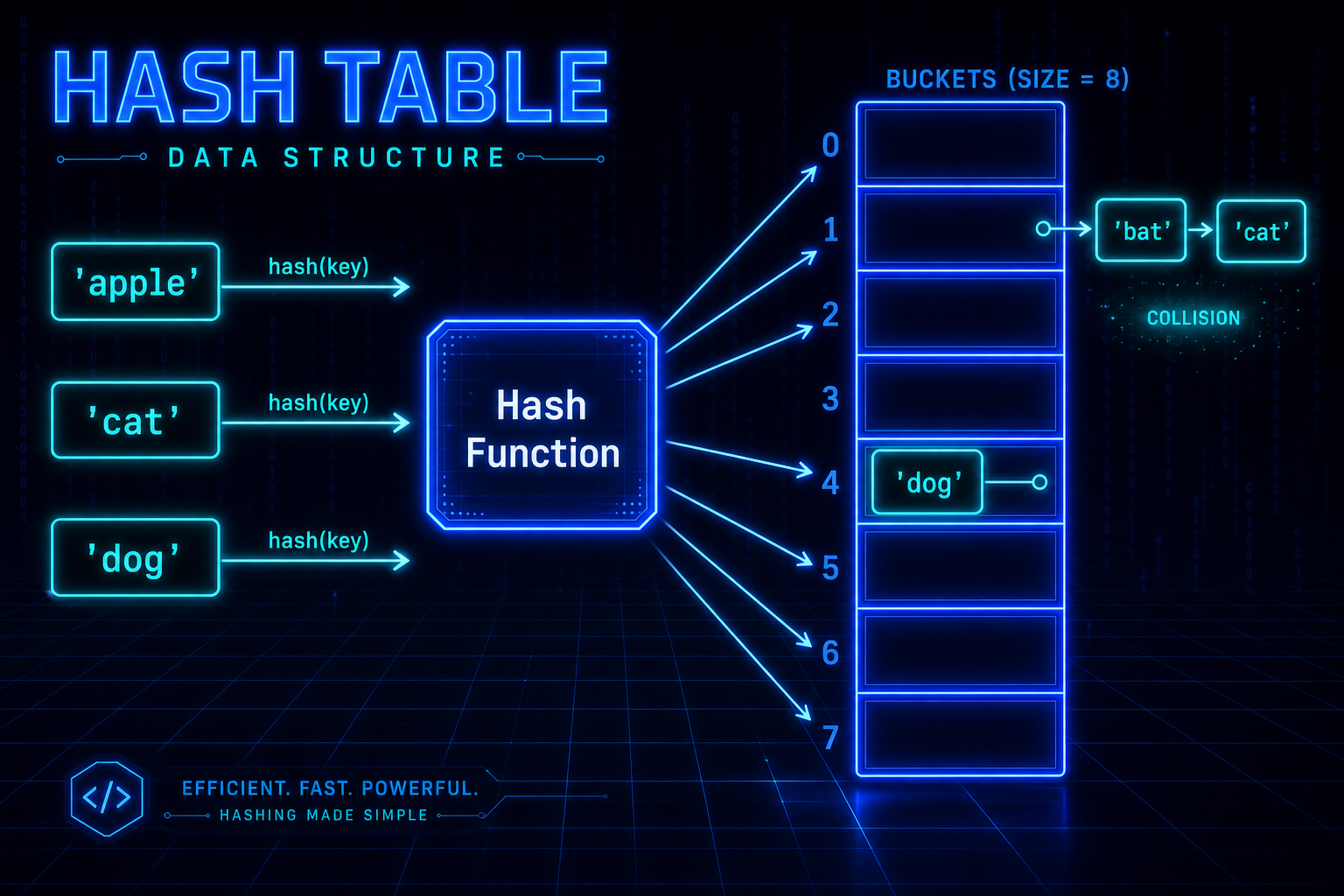
雜湊表(Hash Table) 是資料結構中最強大的工具之一——透過 雜湊函數(Hash Function) 將 key 直接映射到記憶體位置,讓插入、搜尋、刪除的平均時間複雜度都達到 O(1)。無論是資料庫索引、快取系統、還是去重計數,雜湊表幾乎無所不在。本文將帶你從原理到實作,完整掌握雜湊表的核心機制與面試考點。
前言
想像你在管理一間圖書館,書架上有幾萬本書。如果依照到館順序排列,每次找書都要從頭翻到尾,O(n) 的效率根本無法接受。換個方式:依照書名首字母分區,每個字母對應一個書架區域,找書時直接跳到對應區域——這就是雜湊表的核心思想。
雜湊表(Hash Table) 是一種以鍵值對(Key-Value Pair) 儲存資料的資料結構。它透過雜湊函數將 key 計算成一個整數索引,再用該索引直接定位到記憶體中的對應位置(稱為 Bucket),從而實現平均 O(1) 的存取效率。
讀完這篇文章,你將學會:
- 雜湊函數的設計原則與評判標準
- 碰撞(Collision)的成因與兩大處理策略:Chaining 和 Open Addressing
- Load Factor 與 Rehashing 的觸發時機
- 用 TypeScript 從零手刻一個
HashMap類別 - C++
std::unordered_map的正確使用方式與自訂雜湊 - Bloom Filter 等進階變體的原理與應用場景
- 五題 LeetCode 核心面試題的解題思路
核心概念:雜湊表是如何運作的?
雜湊函數(Hash Function)
雜湊函數的任務是:給定任意一個 key,計算出一個落在 [0, bucket數量-1] 範圍內的整數索引。一個好的雜湊函數需要滿足:
- 確定性:同一個 key 每次都回傳相同索引
- 均勻分布:不同 key 應盡量分散到不同的 bucket,避免集中
- 計算快速:計算本身不能成為瓶頸
以字串雜湊為例,常見的 djb2 演算法如下:
function hash(key: string, capacity: number): number {
let hashCode = 0;
for (let i = 0; i < key.length; i++) {
// 左移 5 位等同於 ×32,再減去自身等同於 ×31
hashCode = (hashCode << 5) - hashCode + key.charCodeAt(i);
hashCode |= 0; // 轉為 32-bit 整數,防止溢位
}
return Math.abs(hashCode) % capacity;
}
console.log(hash("apple", 8)); // 例如輸出:0
console.log(hash("bat", 8)); // 例如輸出:1
console.log(hash("cat", 8)); // 例如輸出:1 ← 與 "bat" 碰撞!
碰撞(Collision)——不可避免的麻煩
碰撞是指兩個不同的 key 被雜湊函數映射到同一個 bucket 索引。根據鴿巢原理(Pigeonhole Principle),只要 key 的數量超過 bucket 數量,碰撞就必然發生。解決碰撞的策略分為兩大流派:
策略一:Chaining(鏈結串列法)
每個 bucket 儲存一條鏈結串列,碰撞的元素依序掛在串列後方。
Bucket 陣列(大小 = 8)
index 0: → ["apple" → 1] → null
index 1: → ["bat" → 5] → ["cat" → 3] → null ← 碰撞,掛鏈!
index 2: → null
index 3: → ["dog" → 7] → null
index 4: → null
index 5: → ["egg" → 2] → null
index 6: → null
index 7: → ["fig" → 9] → null
- 優點:實作簡單;即使 Load Factor 超過 1.0 也能正常運作;不同 key 相互獨立
- 缺點:每個節點都需要額外的指標空間;鏈結串列分散於記憶體中,快取命中率低
Java HashMap、Python dict(3.6 之前) 採用此策略。
策略二:Open Addressing(開放定址法)
碰撞時不額外開闢空間,而是在現有陣列中繼續探測(Probe)下一個空位。有三種探測方式:
Linear Probing(線性探測)
next = (hash(k) + i) % n,i = 1, 2, 3...
優點:簡單;快取友好(連續記憶體)
缺點:Primary Clustering(群聚現象),碰撞越多越嚴重
index: 0 1 2 3 4 5 6 7
[_] [A] [B] [C] [_] [_] [_] [_]
↑ 碰撞 碰撞
A → 移到 2 → 移到 3
Quadratic Probing(二次探測)
next = (hash(k) + i²) % n,i = 1, 2, 3...
優點:緩解 Primary Clustering
缺點:Secondary Clustering 仍可能發生
Double Hashing(雙重雜湊)
next = (hash1(k) + i × hash2(k)) % n
優點:最佳分散效果,幾乎無群聚
缺點:需計算兩次雜湊,實作較複雜
Python dict(3.6+)、Ruby Hash 採用 Open Addressing 的變體。
負載因子(Load Factor)與動態擴容(Rehashing)
負載因子(Load Factor) α 衡量雜湊表的飽和程度:
α = 已存入的元素數量 n / Bucket 總數量 m
α 越大 → 碰撞機率越高 → 效能退化
α 越小 → 空間浪費嚴重
當 α 超過閾值時,觸發 Rehashing:建立一個約 2 倍大小的新陣列,將所有現有元素重新計算雜湊並插入。由於 capacity 改變,每個 key 的 bucket 索引都可能不同。
常見閾值設定:
Java HashMap:α > 0.75 觸發擴容
Python dict:α > 0.66(約 2/3)觸發擴容
Chaining 策略:α > 0.7 時效能開始顯著下降
Open Addressing:α > 0.5~0.6 就需要擴容(探測距離急增)
TypeScript 完整實作
手刻 HashMap(Chaining 版)
interface KeyValuePair<K, V> {
key: K;
value: V;
}
class HashMap<K, V> {
private buckets: Array<Array<KeyValuePair<K, V>>>;
private size: number;
private capacity: number;
private readonly LOAD_FACTOR_THRESHOLD = 0.75;
constructor(initialCapacity: number = 16) {
this.capacity = initialCapacity;
this.size = 0;
this.buckets = Array.from({ length: this.capacity }, () => []);
}
// djb2 雜湊演算法
private hash(key: K): number {
const str = String(key);
let hash = 0;
for (let i = 0; i < str.length; i++) {
hash = (hash << 5) - hash + str.charCodeAt(i);
hash |= 0; // 轉為 32-bit integer
}
return Math.abs(hash) % this.capacity;
}
set(key: K, value: V): void {
const index = this.hash(key);
const bucket = this.buckets[index];
// 若 key 已存在則更新值
for (const pair of bucket) {
if (pair.key === key) {
pair.value = value;
return;
}
}
// 否則新增到鏈結串列尾端
bucket.push({ key, value });
this.size++;
// 超過負載因子閾值時觸發擴容
if (this.size / this.capacity > this.LOAD_FACTOR_THRESHOLD) {
this.resize();
}
}
get(key: K): V | undefined {
const index = this.hash(key);
const bucket = this.buckets[index];
for (const pair of bucket) {
if (pair.key === key) {
return pair.value;
}
}
return undefined;
}
delete(key: K): boolean {
const index = this.hash(key);
const bucket = this.buckets[index];
const pairIndex = bucket.findIndex((pair) => pair.key === key);
if (pairIndex === -1) return false;
bucket.splice(pairIndex, 1);
this.size--;
return true;
}
has(key: K): boolean {
return this.get(key) !== undefined;
}
getSize(): number {
return this.size;
}
// Rehashing:建立 2 倍大的新陣列並重新插入所有元素
private resize(): void {
const oldBuckets = this.buckets;
this.capacity *= 2;
this.buckets = Array.from({ length: this.capacity }, () => []);
this.size = 0;
for (const bucket of oldBuckets) {
for (const pair of bucket) {
this.set(pair.key, pair.value);
}
}
}
}
// 使用範例
const map = new HashMap<string, number>();
map.set("apple", 1);
map.set("banana", 2);
map.set("cherry", 3);
console.log(map.get("banana")); // 2
console.log(map.has("cherry")); // true
map.delete("banana");
console.log(map.has("banana")); // false
console.log(map.getSize()); // 2
手刻 HashSet(基於 HashMap)
HashSet 的本質是只儲存 key、value 固定為 true 的 HashMap:
class HashSet<T> {
private map: HashMap<T, boolean>;
constructor() {
this.map = new HashMap<T, boolean>();
}
add(value: T): void {
this.map.set(value, true);
}
has(value: T): boolean {
return this.map.has(value);
}
delete(value: T): boolean {
return this.map.delete(value);
}
getSize(): number {
return this.map.getSize();
}
}
// 使用範例:O(1) 去重
const seen = new HashSet<number>();
const nums = [1, 2, 3, 2, 1, 4];
const unique = nums.filter((n) => {
if (seen.has(n)) return false;
seen.add(n);
return true;
});
console.log(unique); // [1, 2, 3, 4]
JavaScript Map / Set / WeakMap 實務用法
在實際開發中,直接使用內建的 Map 和 Set 即可。與普通物件({})相比,Map 有以下優勢:
// Object 的限制:key 只能是字串或 Symbol
const obj: Record<string, number> = {};
const key1 = { x: 1 };
const key2 = { x: 2 };
obj[key1 as any] = 1;
obj[key2 as any] = 2;
// 兩個物件 key 都被 toString() 成 "[object Object]"
console.log(Object.keys(obj).length); // 1,錯誤!
// Map 的優勢:key 可以是任意型別
const map = new Map<object, number>();
map.set(key1, 1);
map.set(key2, 2);
console.log(map.size); // 2,正確
// WeakMap:key 只能是物件,且為弱引用(不阻止 GC)
// 適合儲存物件的私有元資料,不會造成記憶體洩漏
const metadata = new WeakMap<object, string>();
let user = { name: "Alice" };
metadata.set(user, "admin");
console.log(metadata.get(user)); // "admin"
user = null as any; // user 物件被 GC 回收,WeakMap 中的條目自動清除
選擇指南:
| 需求 | 推薦 |
|---|---|
| key 為字串,快速查找 | Map 或 Object |
| key 為任意型別(物件、函數) | Map |
| 只需要記錄「是否存在」 | Set |
| 儲存物件元資料,不想影響 GC | WeakMap |
| 追蹤物件集合,不想影響 GC | WeakSet |
C++ 對照:unordered_map 與自訂雜湊
基本用法
#include <unordered_map>
#include <unordered_set>
#include <string>
#include <iostream>
#include <vector>
void basicUsage() {
std::unordered_map<std::string, int> freq;
std::vector<std::string> words = {"apple", "banana", "apple", "cherry"};
for (const auto& w : words) {
freq[w]++; // operator[] 對不存在的 key 預設初始化為 0
}
// 安全查詢(find 不插入預設值,operator[] 會)
if (auto it = freq.find("apple"); it != freq.end()) {
std::cout << "apple: " << it->second << "\n"; // apple: 2
}
// C++17 結構化綁定遍歷(順序不保證)
for (const auto& [key, value] : freq) {
std::cout << key << " -> " << value << "\n";
}
}
自訂雜湊函數(用於自訂型別)
C++ 的 unordered_map 要求 key 型別有對應的 std::hash 特化。對於自訂的 struct,需要手動提供:
struct Point {
int x, y;
bool operator==(const Point& other) const {
return x == other.x && y == other.y;
}
};
struct PointHash {
size_t operator()(const Point& p) const {
// 使用 XOR + 位移組合兩個整數的雜湊,避免 {1,2} 和 {2,1} 相同
size_t h1 = std::hash<int>{}(p.x);
size_t h2 = std::hash<int>{}(p.y);
return h1 ^ (h2 << 32) ^ (h2 >> 32);
}
};
void customHashExample() {
std::unordered_set<Point, PointHash> points;
points.insert({1, 2});
points.insert({3, 4});
points.insert({1, 2}); // 重複,不會插入
std::cout << "Unique points: " << points.size() << "\n"; // 2
}
std::map vs std::unordered_map 選擇指南
┌─────────────────┬──────────────────┬───────────────────┐
│ 特性 │ std::map │ std::unordered_map│
├─────────────────┼──────────────────┼───────────────────┤
│ 底層結構 │ Red-Black Tree │ Hash Table │
│ 插入/查詢 │ O(log n) │ O(1) 平均 │
│ 順序保證 │ 有序(key 排序) │ 無序 │
│ 範圍查詢 │ 支援 │ 不支援 │
│ key 需求 │ 需要 < 運算子 │ 需要 hash + == │
│ 記憶體 │ 較多(指標) │ 較少(陣列) │
└─────────────────┴──────────────────┴───────────────────┘
選 std::map:需要有序遍歷、範圍查詢(lower_bound / upper_bound)
選 std::unordered_map:只需 O(1) 查找、不在乎順序
複雜度分析
| 操作 | 平均時間 | 最差時間 | 說明 |
|---|---|---|---|
insert | O(1) | O(n) | 最差:所有 key 碰撞到同一 bucket |
search | O(1) | O(n) | 最差:遍歷整條鏈結串列 |
delete | O(1) | O(n) | 同 search |
resize | O(n) | O(n) | Rehashing 需重建整張表 |
| 空間 | O(n) | O(n) | n 為 Key-Value 對數量 |
最差情況幾乎不會發生:優秀的雜湊函數 + 合適的 Load Factor 閾值(0.7 左右),可將碰撞機率控制在極低水準。
變體與延伸
Bloom Filter(布隆過濾器)
Bloom Filter 是雜湊表的空間極省變體,以極小的記憶體判斷「元素一定不在集合中」或「元素可能在集合中」:
class BloomFilter {
private bits: Uint8Array;
private size: number;
private hashFunctions: number;
constructor(size: number = 1024, hashFunctions: number = 3) {
this.size = size;
this.hashFunctions = hashFunctions;
this.bits = new Uint8Array(Math.ceil(size / 8));
}
private getBit(index: number): boolean {
const byteIndex = Math.floor(index / 8);
const bitIndex = index % 8;
return (this.bits[byteIndex] & (1 << bitIndex)) !== 0;
}
private setBit(index: number): void {
const byteIndex = Math.floor(index / 8);
const bitIndex = index % 8;
this.bits[byteIndex] |= 1 << bitIndex;
}
private hash(str: string, seed: number): number {
let hash = seed;
for (let i = 0; i < str.length; i++) {
hash = (hash * 31 + str.charCodeAt(i)) % this.size;
}
return Math.abs(hash);
}
add(item: string): void {
for (let i = 0; i < this.hashFunctions; i++) {
const index = this.hash(item, i * 2654435761);
this.setBit(index);
}
}
// false → 一定不在集合中(100% 確定)
// true → 可能在集合中(有假陽性風險)
mightContain(item: string): boolean {
for (let i = 0; i < this.hashFunctions; i++) {
const index = this.hash(item, i * 2654435761);
if (!this.getBit(index)) return false;
}
return true;
}
}
// 爬蟲去重範例:節省 10-20 倍記憶體
const visitedFilter = new BloomFilter(1_000_000, 5);
visitedFilter.add("https://example.com/page1");
visitedFilter.add("https://example.com/page2");
console.log(visitedFilter.mightContain("https://example.com/page1")); // true(已訪問)
console.log(visitedFilter.mightContain("https://example.com/page99")); // false(一定未訪問)
核心特性:
- 假陽性(False Positive):
mightContain可能回傳true,但元素實際不在集合中(誤報率可透過調整 size 和 hashFunctions 數量控制) - 無假陰性(False Negative):回傳
false時,元素 100% 不在 集合中 - 無法刪除:一旦設定的 bit 無法取消(刪除會影響其他元素)
- 應用場景:Google Chrome 安全瀏覽黑名單、資料庫 SSTable 快速過濾、爬蟲去重
Robin Hood Hashing
Open Addressing 的改良版。插入時比較新元素與現有元素的探測距離(Probe Distance),若新元素探測距離較長(更「可憐」),則互換位置,讓各元素的探測距離更均勻。
Rust 標準函式庫的 HashMap、Google Abseil 採用此策略,兼顧記憶體緊湊與效能穩定。
Cuckoo Hashing(布穀鳥雜湊)
使用兩個獨立的雜湊函數,每個 key 有兩個候選位置。插入時若兩個位置都被佔,就把現有元素「踢走」到其另一個候選位——如同布穀鳥把別人的蛋踢出巢。
- 最差查詢 O(1):只需檢查兩個固定位置(優於 Chaining 的鏈結串列遍歷)
- 缺點:插入流程較複雜,極端情況下需要整體 Rehashing
面試核心考點
兩數之和(Two Sum)—— LeetCode 1
思路:暴力解需 O(n²) 兩層迴圈。改用 HashMap 記錄「已見過的數字 → 其索引」,遍歷時查找「目標值 - 當前數字」是否存在,一次遍歷 O(n) 解決。
function twoSum(nums: number[], target: number): number[] {
// key: 已看過的數值, value: 其在 nums 中的索引
const seen = new Map<number, number>();
for (let i = 0; i < nums.length; i++) {
const complement = target - nums[i];
if (seen.has(complement)) {
return [seen.get(complement)!, i]; // 找到!
}
seen.set(nums[i], i); // 記錄當前數值
}
return []; // 題目保證有解,不會到這裡
}
console.log(twoSum([2, 7, 11, 15], 9)); // [0, 1](2 + 7 = 9)
console.log(twoSum([3, 2, 4], 6)); // [1, 2](2 + 4 = 6)
字母異位詞分組(Group Anagrams)—— LeetCode 49
思路:兩個字串互為 Anagram 的充要條件是:排序後相同。以「排序後的字串」為 key,將原字串歸組。
function groupAnagrams(strs: string[]): string[][] {
const groups = new Map<string, string[]>();
for (const str of strs) {
// 排序字串作為 key("eat" → "aet","tea" → "aet")
const key = str.split("").sort().join("");
if (!groups.has(key)) {
groups.set(key, []);
}
groups.get(key)!.push(str);
}
return Array.from(groups.values());
}
console.log(groupAnagrams(["eat", "tea", "tan", "ate", "nat", "bat"]));
// [["eat","tea","ate"], ["tan","nat"], ["bat"]]
最長連續序列(Longest Consecutive Sequence)—— LeetCode 128
思路:先將所有數放入 Set,再從每個「序列起點」(即 num - 1 不在 Set 中的數)往右延伸計算長度,整體 O(n)——每個數字最多被訪問兩次。
function longestConsecutive(nums: number[]): number {
const numSet = new Set<number>(nums);
let maxLen = 0;
for (const num of numSet) {
// 只從序列起點開始,避免重複計算中間段
if (numSet.has(num - 1)) continue;
let currentNum = num;
let currentLen = 1;
while (numSet.has(currentNum + 1)) {
currentNum++;
currentLen++;
}
maxLen = Math.max(maxLen, currentLen);
}
return maxLen;
}
console.log(longestConsecutive([100, 4, 200, 1, 3, 2])); // 4(序列:1,2,3,4)
console.log(longestConsecutive([0, 3, 7, 2, 5, 8, 4, 6, 0, 1])); // 9
複雜度:時間 O(n)、空間 O(n)
LRU Cache —— LeetCode 146
思路:需要 O(1) 的 get 與 put。用 HashMap + 雙向鏈結串列(Doubly Linked List) 組合:
HashMap:存key → DLL 節點,O(1) 查找DLL:維護存取順序,最近使用放頭部、最久未使用在尾部,O(1) 移動節點
class DLLNode {
key: number;
value: number;
prev: DLLNode | null = null;
next: DLLNode | null = null;
constructor(key: number, value: number) {
this.key = key;
this.value = value;
}
}
class LRUCache {
private capacity: number;
private cache: Map<number, DLLNode>;
private head: DLLNode; // 啞頭節點(最近使用端)
private tail: DLLNode; // 啞尾節點(最久未使用端)
constructor(capacity: number) {
this.capacity = capacity;
this.cache = new Map();
this.head = new DLLNode(0, 0);
this.tail = new DLLNode(0, 0);
this.head.next = this.tail;
this.tail.prev = this.head;
}
private removeNode(node: DLLNode): void {
node.prev!.next = node.next;
node.next!.prev = node.prev;
}
private addToFront(node: DLLNode): void {
node.next = this.head.next;
node.prev = this.head;
this.head.next!.prev = node;
this.head.next = node;
}
get(key: number): number {
if (!this.cache.has(key)) return -1;
const node = this.cache.get(key)!;
this.removeNode(node); // 從原位置移除
this.addToFront(node); // 移到最前(標記為最近使用)
return node.value;
}
put(key: number, value: number): void {
if (this.cache.has(key)) {
const node = this.cache.get(key)!;
node.value = value;
this.removeNode(node);
this.addToFront(node);
} else {
if (this.cache.size >= this.capacity) {
// 移除最久未使用(tail 的前一個節點)
const lru = this.tail.prev!;
this.removeNode(lru);
this.cache.delete(lru.key);
}
const newNode = new DLLNode(key, value);
this.cache.set(key, newNode);
this.addToFront(newNode);
}
}
}
// 測試
const lru = new LRUCache(2);
lru.put(1, 1);
lru.put(2, 2);
console.log(lru.get(1)); // 1(存取後 1 變為最近使用)
lru.put(3, 3); // 容量滿,淘汰最久未使用的 key=2
console.log(lru.get(2)); // -1(key=2 已被淘汰)
console.log(lru.get(3)); // 3
複雜度:時間 O(1) 的 get 與 put;空間 O(capacity)
Insert Delete GetRandom O(1) —— LeetCode 380
思路:getRandom() 需要 O(1) 隨機存取 → 只有陣列能做到。delete() 用陣列的話是 O(n)(移動元素)→ 技巧:用最後一個元素覆蓋被刪元素,再 pop,O(1)。用 HashMap 維護 val → 陣列索引 的映射,保持同步。
class RandomizedSet {
private valToIndex: Map<number, number>;
private vals: number[];
constructor() {
this.valToIndex = new Map();
this.vals = [];
}
insert(val: number): boolean {
if (this.valToIndex.has(val)) return false;
this.vals.push(val);
this.valToIndex.set(val, this.vals.length - 1);
return true;
}
remove(val: number): boolean {
if (!this.valToIndex.has(val)) return false;
const idx = this.valToIndex.get(val)!;
const lastVal = this.vals[this.vals.length - 1];
// 用最後元素覆蓋被刪元素的位置
this.vals[idx] = lastVal;
this.valToIndex.set(lastVal, idx); // 關鍵:更新 lastVal 的新索引
// 移除最後元素
this.vals.pop();
this.valToIndex.delete(val);
return true;
}
getRandom(): number {
const idx = Math.floor(Math.random() * this.vals.length);
return this.vals[idx];
}
}
// 測試
const rs = new RandomizedSet();
console.log(rs.insert(1)); // true
console.log(rs.insert(2)); // true
console.log(rs.insert(1)); // false(已存在)
console.log(rs.remove(1)); // true
console.log(rs.getRandom()); // 2(只剩 2)
複雜度:insert、remove、getRandom 全部 O(1);空間 O(n)
LeetCode 練習題單
| # | 題目 | 難度 | 核心技巧 |
|---|---|---|---|
| 1 | Two Sum | Easy | 補數查找,一次遍歷 HashMap |
| 49 | Group Anagrams | Medium | 排序字串作為 key 歸組 |
| 128 | Longest Consecutive Sequence | Medium | HashSet + 從序列起點延伸 |
| 146 | LRU Cache | Medium | HashMap + 雙向鏈結串列 |
| 380 | Insert Delete GetRandom O(1) | Medium | HashMap + Array,刪除時交換末位 |
常見陷阱整理
陷阱 1:用物件({})代替 Map,物件作為 key 會被轉為字串
// 錯誤:所有物件 key 都變成 "[object Object]"
const wrong: Record<string, number> = {};
wrong[{ x: 1 } as any] = 1;
wrong[{ x: 2 } as any] = 2;
console.log(Object.keys(wrong).length); // 1(不是 2!)
// 正確:使用 Map
const correct = new Map<object, number>();
correct.set({ x: 1 }, 1);
correct.set({ x: 2 }, 2);
console.log(correct.size); // 2
陷阱 2:LeetCode 380 刪除時忘記更新被移動元素的索引
// 錯誤版本:移動了最後元素,卻沒更新它在 Map 中的新索引
function removeBug(val: number, vals: number[], valToIndex: Map<number, number>): void {
const idx = valToIndex.get(val)!;
vals[idx] = vals[vals.length - 1];
vals.pop();
valToIndex.delete(val);
// 漏了:valToIndex.set(lastVal, idx) ← 導致後續查詢或刪除出錯!
}
陷阱 3:LRU Cache 更新已存在 key 時,忘記移動到最前
// 錯誤:只更新了值,但節點位置沒移動,LRU 順序出錯
function putBug(key: number, value: number): void {
if (cache.has(key)) {
cache.get(key)!.value = value; // 只改值,沒 removeNode + addToFront!
}
}
陷阱 4:誤解 Bloom Filter 的假陽性特性
mightContain() 回傳 true 不代表元素一定存在,只代表「可能存在」。這是設計上的正常行為,不是 bug。降低假陽性率的方法是增大 size 或增加雜湊函數數量 k,理論最佳值為 k = (m/n) × ln2(m 為 bit 數,n 為元素數)。
總結
雜湊表是所有資料結構中「性價比」最高的一個——以 O(n) 空間換取 O(1) 的查找效率,幾乎適用於所有「快速查找」場景。
本文涵蓋的核心知識點:
- 雜湊函數:均勻分布、確定性、計算快速是三大要素
- 碰撞處理:Chaining 簡單靈活;Open Addressing 快取友好但對 Load Factor 敏感
- Load Factor 與 Rehashing:0.75 是業界常用閾值,超過即擴容
- TypeScript 實作:從零手刻 HashMap(含 Rehashing)和 HashSet
- C++ 對照:
std::unordered_mapvsstd::map的選擇策略 - Bloom Filter:極省空間的去重利器,接受假陽性換取極低記憶體佔用
- 五題 LeetCode:Two Sum、Group Anagrams、最長連續序列、LRU Cache、O(1) 隨機集合
下一篇,我們將進入堆積(Heap)與優先佇列(Priority Queue)——當你需要的不只是「查找任意元素」,而是「永遠快速取出最大/最小值」時,它就是最佳選擇。
希望這篇文章能幫助你徹底掌握雜湊表的原理與實作!如有任何問題或想要深入討論的地方,歡迎透過聯絡頁面與我交流。