鏈結串列 — Singly、Doubly、Circular Linked List 完整實作 | 資料結構與演算法
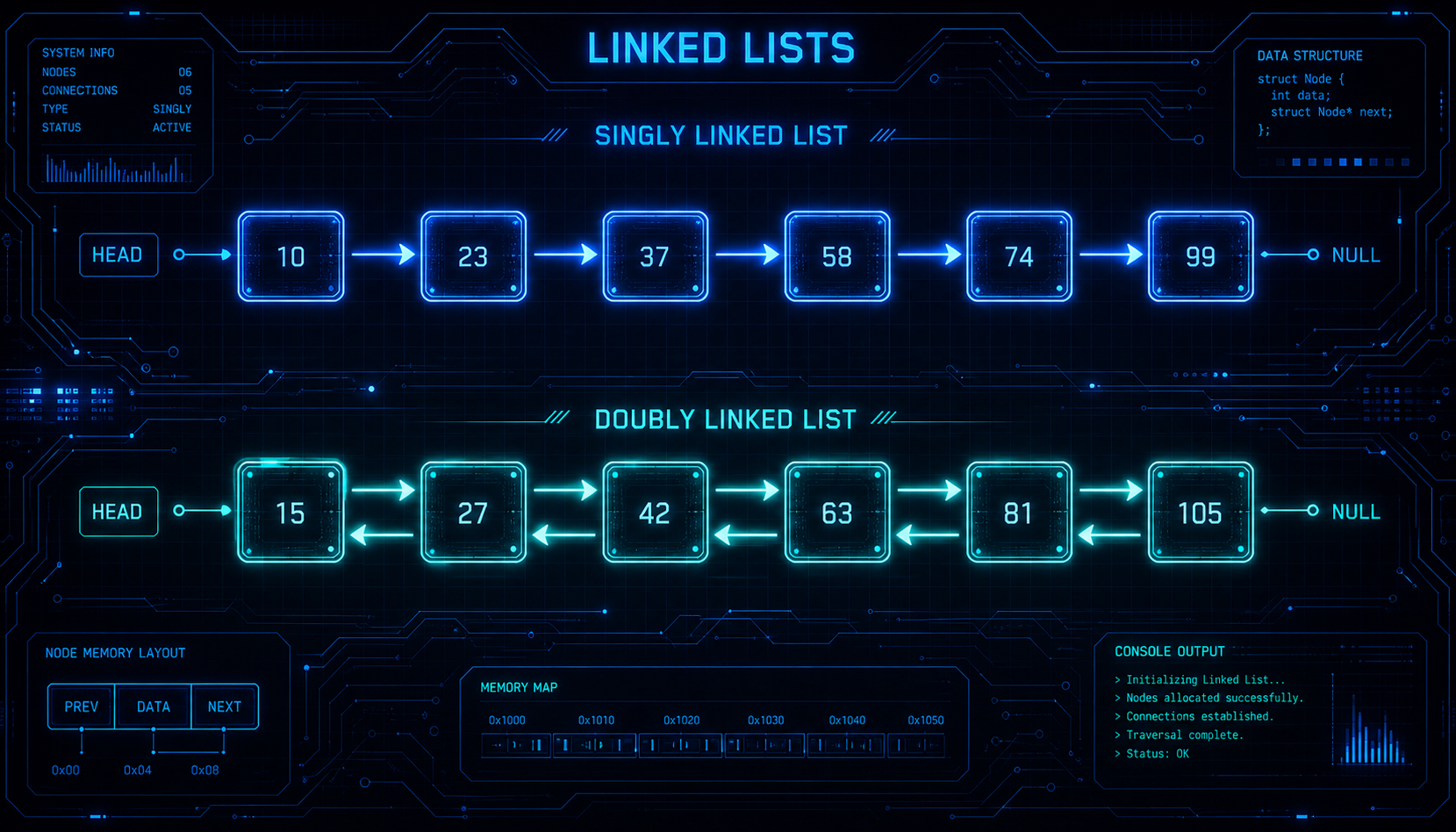
鏈結串列(Linked List) 是由一系列「節點 + 指標」組成的動態線性結構,與 陣列 最大的差異在於:節點不需要連續記憶體,頭部插入與刪除永遠是 O(1)。掌握 單向、雙向、環形 三種鏈結串列的實作,以及 Floyd 快慢指標 等經典技巧,是面試與實務開發的必備基礎。
前言
想像一列火車的車廂:每節車廂(節點)儲存乘客資料(值),並且附有一個告示牌(指標)標示「下一節車廂在哪裡」。你可以在任意位置新增或移除車廂,只需要重新連結告示牌——不需要把後面的車廂全部往前搬。這就是 鏈結串列(Linked List) 的精髓。
相比上一篇介紹的陣列(Array),鏈結串列的記憶體不需要連續,彈性更高,但也付出了隨機存取速度的代價——你必須從頭開始沿著指標一步步走到目標節點,時間複雜度為 O(n)。
本篇是「資料結構與演算法」系列的第 003 篇,讀完你將能夠:
- 理解鏈結串列節點結構與非連續記憶體佈局
- 分辨並實作單向(Singly)、雙向(Doubly)、環形(Circular)三種鏈結串列
- 以 TypeScript 完整實作各項操作(push / pop / insert / remove / reverse)
- 對照 C++ 的 raw pointer 與
std::shared_ptr管理方式 - 掌握 Floyd 龜兔演算法(快慢指標)偵測環
- 應對 LeetCode 高頻鏈結串列題型
核心概念
節點結構與記憶體佈局
鏈結串列的最小單位是 節點(Node),每個節點包含:
- val:儲存的資料值
- next:指向下一個節點的指標(雙向鏈結串列還有 prev)
鏈結串列節點在記憶體中的樣貌(非連續):
┌────────┬──────┐ ┌────────┬──────┐ ┌────────┬──────┐
│ val:1 │ next─┼───────>│ val:2 │ next─┼───────>│ val:3 │ null │
└────────┴──────┘ └────────┴──────┘ └────────┴──────┘
0x1000 0x3F80 0x0A24
(記憶體位址分散,透過指標串聯形成邏輯序列)
對比陣列的連續記憶體,鏈結串列的節點可以散落在記憶體任何地方,動態分配、動態釋放。這讓插入和刪除操作只需更新指標,不需要搬移大量元素。
三種鏈結串列
單向鏈結串列(Singly Linked List):每個節點只有 next 指標,只能從頭到尾單向遍歷。
[head]
│
▼
[1 │ next] ──→ [2 │ next] ──→ [3 │ next] ──→ null
雙向鏈結串列(Doubly Linked List):每個節點同時有 prev 與 next 指標,可雙向遍歷,尾部刪除也只需 O(1)(持有 tail 指標時)。
[head] [tail]
│ │
▼ ▼
null ←── [prev │ 1 │ next] ←──→ [prev │ 2 │ next] ←──→ [prev │ 3 │ next] ──→ null
環形鏈結串列(Circular Linked List):尾節點的 next 指回頭節點,形成環狀循環。常用於輪詢排程(Round Robin)等需要循環結構的場景。
┌──────────────────────────────────────────────┐
│ │
▼ │
[1 │ next] ──→ [2 │ next] ──→ [3 │ next] ────── ┘
JavaScript / TypeScript 實作
節點類別(ListNode)
所有鏈結串列都從節點定義開始:
// 泛型節點,可儲存任意型別的值
class ListNode<T> {
val: T;
next: ListNode<T> | null;
constructor(val: T, next: ListNode<T> | null = null) {
this.val = val;
this.next = next;
}
}
// 工具函式:陣列轉鏈結串列(除錯與測試用)
function arrayToList<T>(arr: T[]): ListNode<T> | null {
if (arr.length === 0) return null;
const dummy = new ListNode<T>(arr[0]);
let cur = dummy;
for (let i = 1; i < arr.length; i++) {
cur.next = new ListNode<T>(arr[i]);
cur = cur.next;
}
return dummy;
}
// 工具函式:鏈結串列轉陣列(方便印出驗證)
function listToArray<T>(head: ListNode<T> | null): T[] {
const result: T[] = [];
let cur = head;
while (cur !== null) {
result.push(cur.val);
cur = cur.next;
}
return result;
}
單向鏈結串列完整實作
class SinglyLinkedList<T> {
head: ListNode<T> | null = null;
tail: ListNode<T> | null = null;
length: number = 0;
// push:在尾部新增節點,O(1)
push(val: T): void {
const node = new ListNode<T>(val);
if (this.tail === null) {
this.head = node;
this.tail = node;
} else {
this.tail.next = node;
this.tail = node;
}
this.length++;
}
// pop:移除並回傳尾部節點,O(n)(需找到倒數第二個節點)
pop(): T | null {
if (this.head === null) return null;
// 只有一個節點時
if (this.head === this.tail) {
const val = this.head.val;
this.head = null;
this.tail = null;
this.length--;
return val;
}
// 找到倒數第二個節點
let cur = this.head;
while (cur.next !== this.tail) {
cur = cur.next!;
}
const val = this.tail!.val;
cur.next = null;
this.tail = cur;
this.length--;
return val;
}
// unshift:在頭部新增節點,O(1)
unshift(val: T): void {
const node = new ListNode<T>(val);
if (this.head === null) {
this.head = node;
this.tail = node;
} else {
node.next = this.head;
this.head = node;
}
this.length++;
}
// shift:移除並回傳頭部節點,O(1)
shift(): T | null {
if (this.head === null) return null;
const val = this.head.val;
this.head = this.head.next;
if (this.head === null) this.tail = null;
this.length--;
return val;
}
// find:根據索引查找節點,O(n)
find(index: number): ListNode<T> | null {
if (index < 0 || index >= this.length) return null;
let cur = this.head;
for (let i = 0; i < index; i++) {
cur = cur!.next;
}
return cur;
}
// insert:在指定索引前插入節點,O(n)
insert(index: number, val: T): boolean {
if (index < 0 || index > this.length) return false;
if (index === 0) { this.unshift(val); return true; }
if (index === this.length) { this.push(val); return true; }
const prev = this.find(index - 1)!;
const node = new ListNode<T>(val);
node.next = prev.next;
prev.next = node;
this.length++;
return true;
}
// remove:移除指定索引的節點,O(n)
remove(index: number): T | null {
if (index < 0 || index >= this.length) return null;
if (index === 0) return this.shift();
if (index === this.length - 1) return this.pop();
const prev = this.find(index - 1)!;
const target = prev.next!;
prev.next = target.next;
target.next = null;
this.length--;
return target.val;
}
// reverse:就地反轉整個鏈結串列,O(n)
reverse(): void {
let prev: ListNode<T> | null = null;
let cur: ListNode<T> | null = this.head;
this.tail = this.head; // 原本的頭變成新的尾
while (cur !== null) {
const next = cur.next; // 先儲存,避免斷鏈後找不到
cur.next = prev; // 反轉指標方向
prev = cur;
cur = next;
}
this.head = prev; // prev 現在是新的 head
}
// toArray:方便除錯的輸出函式
toArray(): T[] {
return listToArray(this.head);
}
}
// 使用範例
const list = new SinglyLinkedList<number>();
list.push(1);
list.push(2);
list.push(3);
list.unshift(0);
console.log(list.toArray()); // [0, 1, 2, 3]
list.reverse();
console.log(list.toArray()); // [3, 2, 1, 0]
list.insert(2, 99);
console.log(list.toArray()); // [3, 2, 99, 1, 0]
list.remove(2);
console.log(list.toArray()); // [3, 2, 1, 0]
雙向鏈結串列(DoublyLinkedList)
雙向鏈結串列的每個節點多了 prev 指標,尾部刪除從 O(n) 降至 O(1),但每次操作都需要同步更新兩個指標方向:
class DoublyNode<T> {
val: T;
prev: DoublyNode<T> | null = null;
next: DoublyNode<T> | null = null;
constructor(val: T) { this.val = val; }
}
class DoublyLinkedList<T> {
head: DoublyNode<T> | null = null;
tail: DoublyNode<T> | null = null;
length: number = 0;
// push:尾部新增,O(1)
push(val: T): void {
const node = new DoublyNode<T>(val);
if (this.tail === null) {
this.head = node;
this.tail = node;
} else {
node.prev = this.tail;
this.tail.next = node;
this.tail = node;
}
this.length++;
}
// pop:尾部移除,O(1)(雙向的優勢)
pop(): T | null {
if (this.tail === null) return null;
const val = this.tail.val;
if (this.head === this.tail) {
this.head = null;
this.tail = null;
} else {
this.tail = this.tail.prev;
this.tail!.next = null;
}
this.length--;
return val;
}
// unshift:頭部新增,O(1)
unshift(val: T): void {
const node = new DoublyNode<T>(val);
if (this.head === null) {
this.head = node;
this.tail = node;
} else {
node.next = this.head;
this.head.prev = node;
this.head = node;
}
this.length++;
}
// shift:頭部移除,O(1)
shift(): T | null {
if (this.head === null) return null;
const val = this.head.val;
if (this.head === this.tail) {
this.head = null;
this.tail = null;
} else {
this.head = this.head.next;
this.head!.prev = null;
}
this.length--;
return val;
}
// toArray:順向印出
toArray(): T[] {
const result: T[] = [];
let cur = this.head;
while (cur !== null) { result.push(cur.val); cur = cur.next; }
return result;
}
// toArrayReverse:逆向印出(雙向的獨有功能)
toArrayReverse(): T[] {
const result: T[] = [];
let cur = this.tail;
while (cur !== null) { result.push(cur.val); cur = cur.prev; }
return result;
}
}
// 使用範例
const dl = new DoublyLinkedList<number>();
dl.push(1); dl.push(2); dl.push(3);
console.log(dl.toArray()); // [1, 2, 3]
console.log(dl.toArrayReverse()); // [3, 2, 1]
dl.pop();
console.log(dl.toArray()); // [1, 2](O(1) 尾部刪除)
環形鏈結串列(CircularLinkedList)
環形鏈結串列的尾節點 next 指回 head,遍歷時必須用節點計數或起點比對來判斷終止條件,否則會無窮迴圈:
class CircularLinkedList<T> {
head: ListNode<T> | null = null;
length: number = 0;
// push:尾部新增並維持環形結構,O(n)(需找尾節點)
push(val: T): void {
const node = new ListNode<T>(val);
if (this.head === null) {
this.head = node;
node.next = this.head; // 指回自己形成環
} else {
// 找到尾節點(next 指回 head 的節點)
let tail = this.head;
while (tail.next !== this.head) {
tail = tail.next!;
}
tail.next = node;
node.next = this.head; // 新尾節點指回 head
}
this.length++;
}
// toArray:安全遍歷,以計數控制終止條件,O(n)
toArray(): T[] {
if (this.head === null) return [];
const result: T[] = [];
let cur = this.head;
let count = 0;
while (count < this.length) {
result.push(cur.val);
cur = cur.next!;
count++;
}
return result;
}
// has:檢查值是否存在,O(n)
has(val: T): boolean {
if (this.head === null) return false;
let cur = this.head;
let count = 0;
while (count < this.length) {
if (cur.val === val) return true;
cur = cur.next!;
count++;
}
return false;
}
}
// 使用範例
const cl = new CircularLinkedList<number>();
cl.push(1); cl.push(2); cl.push(3);
console.log(cl.toArray()); // [1, 2, 3]
console.log(cl.has(2)); // true
C++ 對照實作
Raw Pointer 版本
C++ 的鏈結串列操作直接面對原始指標,必須手動管理記憶體(new / delete),稍有疏失便會造成記憶體洩漏或懸空指標(Dangling Pointer)。
#include <iostream>
// 節點定義
struct ListNode {
int val;
ListNode* next;
explicit ListNode(int v, ListNode* n = nullptr) : val(v), next(n) {}
};
// 反轉鏈結串列(迭代法)
ListNode* reverseList(ListNode* head) {
ListNode* prev = nullptr;
ListNode* cur = head;
while (cur != nullptr) {
ListNode* nextTemp = cur->next; // 先儲存,避免斷鏈
cur->next = prev; // 反轉指標方向
prev = cur;
cur = nextTemp;
}
return prev; // prev 是新的 head
}
// 在頭部插入節點,O(1)
ListNode* insertFront(ListNode* head, int val) {
ListNode* node = new ListNode(val);
node->next = head;
return node; // 回傳新的 head
}
// 刪除指定值的第一個節點,O(n)
ListNode* deleteVal(ListNode* head, int val) {
// 使用虛擬頭節點(dummy node)統一處理刪除 head 的邊界條件
ListNode dummy(0, head);
ListNode* prev = &dummy;
while (prev->next != nullptr) {
if (prev->next->val == val) {
ListNode* toDelete = prev->next;
prev->next = toDelete->next;
delete toDelete; // 手動釋放記憶體
break;
}
prev = prev->next;
}
return dummy.next;
}
// 釋放整個鏈結串列,防止記憶體洩漏
void freeList(ListNode* head) {
while (head != nullptr) {
ListNode* next = head->next;
delete head;
head = next;
}
}
智慧指標版本(std::shared_ptr)
使用 RAII(Resource Acquisition Is Initialization) 原則,透過 std::shared_ptr 讓記憶體自動管理,避免手動 delete 的錯誤:
#include <memory>
struct SmartNode {
int val;
std::shared_ptr<SmartNode> next;
explicit SmartNode(int v) : val(v), next(nullptr) {}
};
// 建立鏈結串列(記憶體由 shared_ptr 自動管理)
std::shared_ptr<SmartNode> buildList(std::vector<int> vals) {
if (vals.empty()) return nullptr;
auto dummy = std::make_shared<SmartNode>(0);
auto cur = dummy;
for (int v : vals) {
cur->next = std::make_shared<SmartNode>(v);
cur = cur->next;
}
return dummy->next;
}
// 注意:shared_ptr 在環形結構中會造成循環引用(circular reference)
// 導致記憶體永遠無法釋放,環形鏈結串列應改用 std::weak_ptr 斷環
std::list 標準函式庫
實務中的 C++ 開發通常直接使用標準函式庫 std::list,它是雙向鏈結串列的完整實作:
#include <list>
#include <algorithm>
#include <iostream>
void stdListDemo() {
std::list<int> lst = {1, 2, 3, 4, 5};
lst.push_front(0); // O(1) 頭部插入 → [0,1,2,3,4,5]
lst.push_back(6); // O(1) 尾部插入 → [0,1,2,3,4,5,6]
// 找到值為 3 的迭代器後 O(1) 刪除
auto it = std::find(lst.begin(), lst.end(), 3);
if (it != lst.end()) lst.erase(it); // → [0,1,2,4,5,6]
for (int v : lst) std::cout << v << " "; // 輸出:0 1 2 4 5 6
}
複雜度分析
各操作在不同鏈結串列類型下的時間複雜度:
| 操作 | Singly(無 tail) | Singly(有 tail) | Doubly(有 tail) | 備註 |
|---|---|---|---|---|
| 頭部插入(unshift) | O(1) | O(1) | O(1) | 更新 head 即可 |
| 頭部刪除(shift) | O(1) | O(1) | O(1) | 更新 head 即可 |
| 尾部插入(push) | O(n) | O(1) | O(1) | 持有 tail 指標 |
| 尾部刪除(pop) | O(n) | O(n) | O(1) | 雙向可直接找前驅 |
| 中間插入 | O(n) | O(n) | O(n) | 需先走訪到位置 |
| 中間刪除 | O(n) | O(n) | O(n) | 需先走訪到位置 |
| 隨機存取(find) | O(n) | O(n) | O(n) | 無法跳躍,只能線性 |
| 搜尋(search) | O(n) | O(n) | O(n) | 線性掃描 |
| 反轉(reverse) | O(n) | O(n) | O(n) | 需走訪全部節點 |
空間複雜度:所有操作均為 O(1) 額外空間(不計節點本身)。
鏈結串列 vs 陣列的選用原則:
- 需要頻繁 頭部插入 / 刪除 → 鏈結串列(O(1) vs 陣列 O(n))
- 需要 隨機存取(按索引取值)→ 陣列(O(1) vs 鏈結串列 O(n))
- 資料量 動態變化,不確定大小 → 鏈結串列(不需預先分配)
- 需要 快取友善(cache-friendly) 的遍歷效能 → 陣列(連續記憶體有更好的快取命中率)
變體與延伸
Skip List(跳躍串列)
Skip List 在有序鏈結串列基礎上,加入多層「快速通道」索引,使搜尋時間從 O(n) 降至期望 O(log n)。Redis 的 Sorted Set 底層即使用 Skip List 實作,兼顧範圍查詢與動態插入的效率。
Level 3: [head] ──────────────────────────────────────────────── [tail]
Level 2: [head] ──────────────── [4] ─────────────────────────── [tail]
Level 1: [head] ──── [2] ──────── [4] ──────────── [7] ─────── [tail]
Level 0: [head] ──── [2] ── [3] ── [4] ── [5] ──── [7] ── [9] ── [tail]
搜尋 7:從最高層快速跳到 4,再往右直接到 7,跳過了 2、3、5——這就是「跳躍」的精髓。
XOR Linked List
XOR Linked List 是一種記憶體最佳化技巧:每個節點只儲存 prev XOR next 的位址(一個整數),讓雙向鏈結串列只需一個指標欄位即可雙向遍歷,節省約一半的指標記憶體。
// 取得 next 的公式:
// next_addr = prev_addr XOR node->both
// 取得 prev 的公式:
// prev_addr = next_addr XOR node->both
代價:可讀性極低,且現代 GC 語言(JavaScript、Java)無法使用,因為 GC 無法追蹤 XOR 混合後的位址。在 C++ 系統程式設計中偶爾可見。
Unrolled Linked List
每個節點儲存一個小型陣列而非單一值,兼顧鏈結串列的彈性與陣列的快取友善性(cache locality),是 B-Tree 的簡化版概念。
常見面試考點
反轉鏈結串列(LeetCode 206)
面試最常考的基礎題。核心技巧是使用三個指標 prev、cur、next,注意必須先儲存 next 再反轉 cur.next,否則會斷鏈:
// 迭代法:O(n) 時間、O(1) 空間
function reverseList(head: ListNode | null): ListNode | null {
let prev: ListNode | null = null;
let cur: ListNode | null = head;
while (cur !== null) {
const next = cur.next; // 先儲存,否則反轉後找不到下一個節點
cur.next = prev; // 反轉指標方向
prev = cur;
cur = next;
}
return prev; // prev 現在是新的 head
}
// 時間:O(n),空間:O(1)
// 遞迴法:O(n) 時間、O(n) 空間(呼叫堆疊)
function reverseListRecursive(head: ListNode | null): ListNode | null {
if (head === null || head.next === null) return head;
const newHead = reverseListRecursive(head.next);
head.next.next = head; // 讓後一個節點指回前一個
head.next = null; // 切斷原本的連結
return newHead;
}
合併兩個有序鏈結串列(LeetCode 21)
關鍵技巧是使用 虛擬頭節點(Dummy Node) 統一處理邊界條件,避免對空串列和頭節點做特殊判斷:
// O(m + n) 時間、O(1) 空間
function mergeTwoLists(
list1: ListNode | null,
list2: ListNode | null
): ListNode | null {
const dummy = new ListNode(0); // 虛擬頭節點,簡化邊界處理
let cur = dummy;
while (list1 !== null && list2 !== null) {
if (list1.val <= list2.val) {
cur.next = list1;
list1 = list1.next;
} else {
cur.next = list2;
list2 = list2.next;
}
cur = cur.next!;
}
cur.next = list1 !== null ? list1 : list2; // 接上剩餘部分
return dummy.next;
}
Floyd 快慢指標偵測環(LeetCode 141 / 142)
Floyd 龜兔演算法(Floyd’s Cycle Detection) 是鏈結串列最經典的雙指標技巧:慢指標每次走一步,快指標每次走兩步。若存在環,兩者必定在環內相遇。
// LeetCode 141 — 偵測是否有環,O(n) 時間、O(1) 空間
function hasCycle(head: ListNode | null): boolean {
let slow: ListNode | null = head;
let fast: ListNode | null = head;
while (fast !== null && fast.next !== null) {
slow = slow!.next; // 龜:每次走一步
fast = fast.next.next; // 兔:每次走兩步
if (slow === fast) return true; // 相遇代表有環
}
return false; // fast 到達 null,無環
}
// LeetCode 142 — 找環的起點(數學推導版)
function detectCycle(head: ListNode | null): ListNode | null {
let slow: ListNode | null = head;
let fast: ListNode | null = head;
// 第一步:快慢指標找相遇點
while (fast !== null && fast.next !== null) {
slow = slow!.next;
fast = fast.next.next;
if (slow === fast) break;
}
if (fast === null || fast.next === null) return null; // 無環
// 第二步:slow 移回 head,fast 留在相遇點
// 兩指標同速前進,會在環的起點再次相遇(數學可證)
slow = head;
while (slow !== fast) {
slow = slow!.next;
fast = fast!.next;
}
return slow; // 環的起點
}
移除倒數第 N 個節點(LeetCode 19)
利用 間距為 N 的雙指標:先讓 fast 指標走 N 步,再讓 slow 與 fast 同速前進直到 fast 到達尾部,此時 slow 就停在目標節點的前一個位置:
// O(n) 時間、O(1) 空間
function removeNthFromEnd(head: ListNode | null, n: number): ListNode | null {
const dummy = new ListNode(0, head); // dummy node 防止刪除 head 的邊界問題
let fast: ListNode | null = dummy;
let slow: ListNode | null = dummy;
// fast 先走 n+1 步(多一步讓 slow 停在前驅節點)
for (let i = 0; i <= n; i++) {
fast = fast!.next;
}
// 同步前進直到 fast 為 null
while (fast !== null) {
slow = slow!.next;
fast = fast.next;
}
// slow 現在是目標節點的前一個,跳過目標節點
slow!.next = slow!.next!.next;
return dummy.next;
}
LeetCode 練習題
以下 5 題是鏈結串列題型的核心訓練,由易到難涵蓋主要解題模式:
| # | 題目 | 難度 | 核心技巧 |
|---|---|---|---|
| 206 | Reverse Linked List | Easy | 三指標迭代 / 遞迴反轉 |
| 21 | Merge Two Sorted Lists | Easy | Dummy node + 雙指標 |
| 141 | Linked List Cycle | Easy | Floyd 快慢指標 |
| 19 | Remove Nth Node From End of List | Medium | 間距 N 的雙指標 |
| 23 | Merge K Sorted Lists | Hard | Min Heap / 分治合併 |
LeetCode 23 — 合併 K 個有序鏈結串列 進階版本使用分治法,兩兩合併達到 O(N log k):
// 分治法:O(N log k) 時間,N 為所有節點總數,k 為串列數量
function mergeKLists(lists: Array<ListNode | null>): ListNode | null {
if (lists.length === 0) return null;
// 合併兩個有序串列的輔助函式
const merge = (l1: ListNode | null, l2: ListNode | null): ListNode | null => {
const dummy = new ListNode(0);
let cur = dummy;
while (l1 && l2) {
if (l1.val <= l2.val) { cur.next = l1; l1 = l1.next; }
else { cur.next = l2; l2 = l2.next; }
cur = cur.next!;
}
cur.next = l1 ?? l2;
return dummy.next;
};
// 逐輪兩兩合併,每輪合併數量減半
let interval = 1;
while (interval < lists.length) {
for (let i = 0; i + interval < lists.length; i += interval * 2) {
lists[i] = merge(lists[i], lists[i + interval]);
}
interval *= 2;
}
return lists[0];
}
常見陷阱
陷阱一:修改 next 前未儲存下一個節點
在反轉或重新連結時,最容易犯的錯誤是先改 cur.next 再嘗試存取原本的 next,此時指標已被覆蓋而找不到後續節點:
// 錯誤:next 被覆蓋後再存取,造成斷鏈
while (cur !== null) {
cur.next = prev; // next 已被覆蓋!
prev = cur;
cur = cur.next; // 這裡拿到的是 prev,不是原本的下一個節點
}
// 正確:先把 next 存起來
while (cur !== null) {
const next = cur.next; // 先保存
cur.next = prev;
prev = cur;
cur = next; // 使用原本保存的 next
}
陷阱二:雙向鏈結串列忘記更新 prev 指標
每次插入或刪除節點,都必須同時維護 next 和 prev 兩個方向:
// 錯誤:只更新 next,忘記更新 prev
function addToFront(node: DoublyNode<number>): void {
node.next = this.head;
// 忘記:node.prev = null;(新 head 的前驅應為 null)
// 忘記:this.head!.prev = node;(原 head 的前驅要指回新節點)
this.head = node;
}
// 正確:四個指標都要更新
function addToFront(node: DoublyNode<number>): void {
node.next = this.head;
node.prev = null;
if (this.head !== null) this.head.prev = node;
this.head = node;
}
陷阱三:環形鏈結串列遍歷無窮迴圈
在有環的鏈結串列上直接用 while (cur !== null) 遍歷,會陷入無窮迴圈。環形鏈結串列的正確遍歷必須用計數或記錄起點作為終止條件:
// 錯誤:在環形串列上死迴圈
while (cur !== null) { // cur 永遠不為 null!
result.push(cur.val);
cur = cur.next;
}
// 正確方式一:計數控制(已知長度時)
let count = 0;
while (count < this.length) {
result.push(cur.val);
cur = cur.next!;
count++;
}
// 正確方式二:記錄起點(未知長度時)
const start = cur;
do {
result.push(cur.val);
cur = cur.next!;
} while (cur !== start);
總結
鏈結串列是資料結構的基石之一,它的核心思想「節點 + 指標」在演算法設計中無處不在。本篇涵蓋了:
- 單向鏈結串列:最基礎的線性節點鏈,頭部操作 O(1),尾部刪除需 O(n)
- 雙向鏈結串列:額外的
prev指標讓尾部操作也達到 O(1),是 LRU Cache 的核心結構 - 環形鏈結串列:尾連頭形成循環,遍歷需特別防範無窮迴圈
- Floyd 快慢指標:O(1) 空間偵測環,是「雙指標」思維的代表性應用
- Dummy Node 技巧:統一處理頭節點邊界條件,讓程式碼更簡潔
下一篇將進入「堆疊(Stack)與佇列(Queue)」——它們正是以鏈結串列(或陣列)為底層,實作出具有特定存取順序限制的資料結構,是 DFS、BFS 等演算法的基礎容器。
希望這篇文章能幫助你建立鏈結串列的完整認識。如果在實作過程中有任何問題或想討論更多進階應用,歡迎至
聯絡頁面留言交流!